我的笔记
数据结构
二叉查找树的时间复杂度是多少?
平衡状态下为 O(logn) 节点分布失衡会退化到 O(n) 在一条链上
在 O(logn) 中的 log 是以什么为底?
以 2 为底 n 的对数 = 以 2 为底 10 的对数 * 以 10 为底 n 的对数
以 2 为底 10 的对数是一个常数,这里忽略常数项系数
log 以 i 为底 n 的对数等于 log 以 j 为底 n 的对数,所以忽略了 i,直接说是logn
这里的 n 是指?
n 个节点
二叉查找树和二分法哪个速度更快?
两者时间复杂度都是 O(logn)
两者明显的区别是二分查找速度快删除和插入困难,对于建立的二叉树索引来说,他的插入和删除是相对较快的。
为什么会出现这两者的差别?
从空间性能,顺序存储会对空间资源做到百分之百的利用,而链式存储对对空间的利用不是百分之百,因为存储了指针,不是真正的数据;
从时间性能上来讲读取速度的话顺序存储更优,插入和删除操作链式存储更优,链式存储只需要移动指针,不需要移动元素。
什么时候采用二分什么时候采用二叉索引?
如果数据是不进行频繁变化且是有序,而且查询相对较多的情况下采用二分查找;
数据是频繁变化的考虑到后面的数据扩容的情况下,考虑采用二叉索引的方式,但是会有一点空间资源的牺牲。
二叉树的遍历方式有哪些?实现一下代码?
前、中、后序遍历
# 二叉树中序遍历的递归 value left right
def inorder(root):
if not root:
return
inorder(root.left)
print(root.val)
inorder(root.right)
# 二叉树先序遍历的递归 left value right
def preorder(root):
if not root:
return
print(root.val)
preorder(root.left)
preorder(root.right)
# 二叉树后序遍历的递归 left right value
def postorder(root):
if not root:
return
postorder(root.left)
postorder(root.right)
print(root.val)
怎么判断二叉树平衡?
左右两个子树的高度差的绝对值均不超过 1
什么是平衡二叉树?
平衡二叉树又叫 AVL 树,是一种特殊的二叉查找树,可以自动调节平衡。
AVL 树维持着严格的平衡,任意节点两颗子树的高度差都不超过 1。
优点是保证了查询效率,缺点是维持平衡成本较高,适合查询较多的场景。
什么是红黑树?
是另一种可以自动调整平衡的二叉查找树。优点是降低了维持平衡的成本,缺点是查询效率底,适合频繁插入删除的场景。
红黑树和AVL树的不同?
AVL是严格平衡树,因此在增加或者删除节点的时候,根据不同情况,旋转的次数比红黑树要多;
红黑是用非严格的平衡来换取增删节点时候旋转次数的降低;
红黑树有什么更深刻理解?
红黑树详解: https://xieguanglei.github.io/blog/post/red-black-tree.html
什么是B树和B+树?
B树解决了从磁盘海量数据中查询的需求,有效减少了磁盘 I/O 的频次。
B+树是B树的升级,叶子结点包括全量数据,并使用双向指针连接相邻节点,为范围查询提供了便利。
如何快速判断一个数是奇数还是偶数,除了对2取余?
与1相与。 return 奇数 if( x & 1 ) else 偶数
计算机网络
什么是内网什么是公网?
内网是局域网;公网是互联网。IP地址就像家庭住址一样,公网IP是小区地址,内网IP是具体的门牌号,你可以从小区里走出去(内网IP能连接互联网) 但外人进入你家需要过门岗验证(公网IP无法直接连接内网IP)
什么是端口?端口的范围?
端口应用程序(服务)在计算机中的唯一标识。范围: 0-65535
如何标识唯一标识一个连接?
TCP 连接的四元组——源 IP、源端口、目标 IP 和目标端口。
为什么有 TCP/IP 四层模型?层次结构设计的基本原则是什么?
OSI 七层协议体系结构的概念清楚,理论也比较完整,但它既复杂又不实用。
- 各层之间是相互独立的;
- 每一层需要有足够的灵活性;
- 各层之间完全解耦。
对 TCP/IP 四层模型的理解?
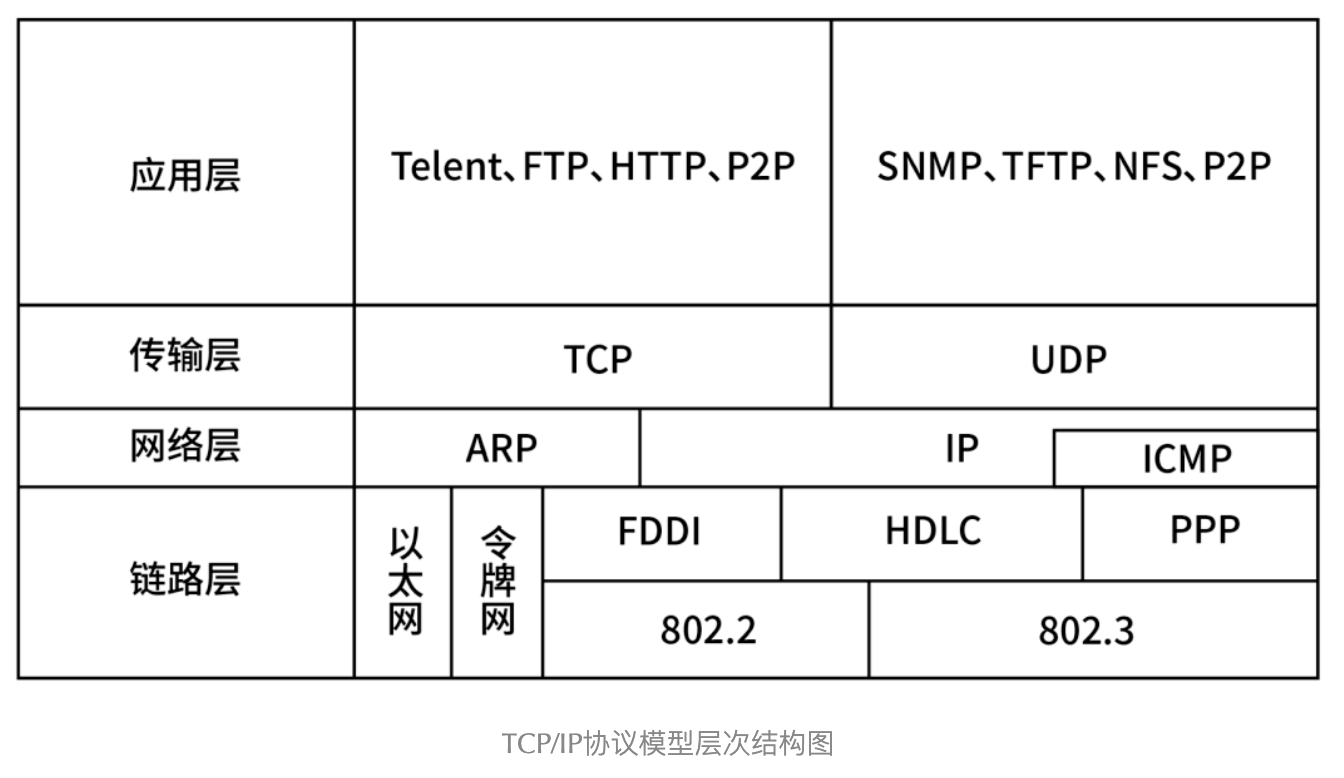
- 应用层(数据段)
- 传输层(数据包)
- 网络层(数据帧)
- 数据链路层(比特流)
对 OSI 七层模型的理解?
-
应用层(文件传输,电子邮件,文件服务,虚拟终端)
协议:TFTP、HTTP、SNMP、FTP、SMTP、DNS、Telnet … -
表示层(数据格式化,代码转换,数据加密)
协议:没有 -
会话层(解除或建立与别的接点的联系)
协议:没有 -
传输层(提供端对端的接口)
协议:TCP、UDP -
网络层(为数据包选择路由)
协议:IP、ICMP、RIP、OSPF、BGP、IGMP …- 路由器
- 拥有独立MAC帮助转发,本身没有传输包的功能实际传输是委托给数据链路层的
- IP协议是不可靠协议,数据处理被认为是上层协议要做的事
- 32位IP地址分为网络位和地址位,这样可以减少路由表记录的数目
- A类IP地址:0.0.0.0 ~ 1 27.0.0.0
- B类IP地址:128.0.0.1 ~ 191.255.0.0
- C类IP地址:192.168.0.0 ~ 239.255.255.0
- 路由器
-
数据链路层(传输有地址的帧以及错误检测功能)
协议:SLIP,CSLIP,PPP,ARP,RARP,MTU- 交换机
- 通过维护一张MAC地址表,只发送给目标MAC地址指向的那一台电脑(以太网)
- 交换机
-
物理层(以二进制数据形式在物理媒体上传输数据)
协议:ISO2110,IEEE802,IEEE802.2- 集线器
- 无脑将信号转发给所有MAC地址
- 集线器
TCP & UDP 的区别
TCP是一个面向连接的、可靠的、基于字节流的传输层协议。而UDP是一个面向无连接的传输层协议
| TCP(Transmission Control Protocol) | UDP | |
|---|---|---|
| 可靠性 | 可靠 | 不可靠 |
| 连接性 | 面向连接 | 无连接 |
| 效率 | 传输效率低 | 传输效率高 |
| 双工性 | 全双工 | 一对一、一对多、多对一、多对多 |
| 传输速度 | 慢 | 快 |
| 应用场景 | 对效率要求低,对准确性要求高或者要求有链接的场景 | 对效率要求高,对准确性要求低的场景 |
| 应用层协议 | SMTP电子邮件/HTTP万维网/FTP文件传输 | DNS域名转换/TFTP文件传输/NFS远程文件服务器 |
- TCP 提供面向连接的传输,通信前要先建立连接(三次握手机制);UDP提供无连接的传输,通信前不需要建立连接。
- TCP 提供可靠的传输(有序,无差错,不丢失,不重复);UDP提供不可靠的传输。
- TCP 面向字节流的传输,因此它能将信息分割成组,并在接收端将其重组;UDP是面向数据报的传输,没有分组开销。
- TCP 提供拥塞控制和流量控制机制;UDP不提供拥塞控制和流量控制机制。
什么是 http 协议,它在哪一层模型中?
Hyper Text Transfer Protocol 超文本传输协议,位于 TCP/IP 四层模型当中的应用层。主要是用途客户端和服务端的沟通。
http 协议的缺点有哪些?
- 窃听风险: 通信使用明文(不加密),内容可能会被窃听;
- 冒充风险: 不验证通信方的身份,因此有可能遭遇伪装;
- 篡改风险: 无法证明报文的完整性,所以有可能已遭篡改;
http 协议不同版本的区别?
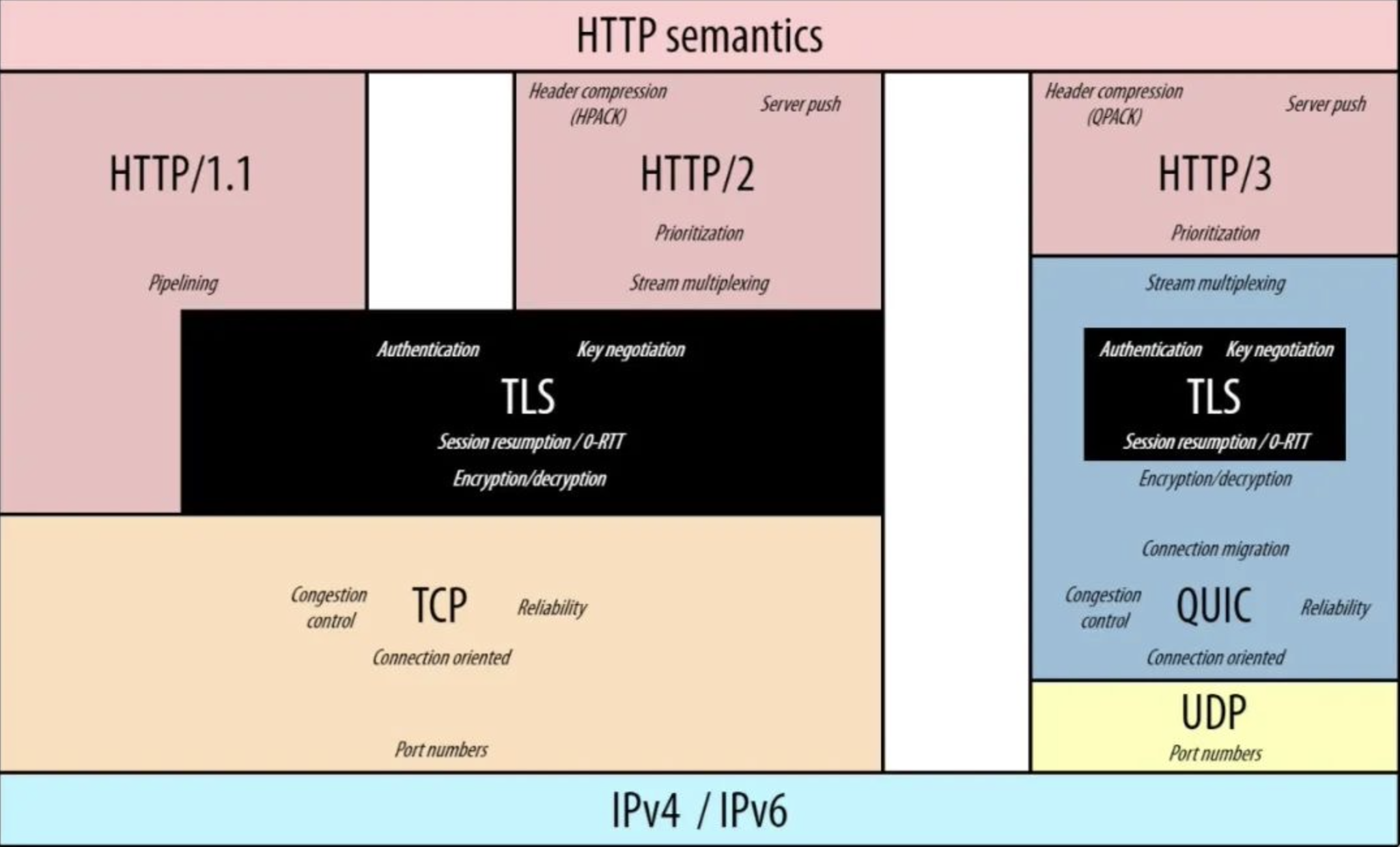
- HTTP/1.1 默认使用长连接,可有效减少TCP的三次握手开销。
- HTTP/1.1 支持只发送header信息(不带任何body信息),如果服务器认为客户端有权限请求服务器,则返回100,否则返回401。客户端接受到100,才开始把请求body发送到服务器。当服务器返回401的时候,客户端可以不用发送请求body了。
- HTTP/2 对 header 压缩;使用多路复用技术,多路复用允许同时通过单一的 HTTP/2 连接发起多重的请求-响应消息。
- HTTP/3 是基于 QUIC 传输协议的,具有 HTTP 传输所需的几个特性,例如多路复用、流量控制、每个流的流控制和低延迟连接建立。
一次完整 HTTP 建立连接所经历的步骤?
- 由域名→ IP 地址 寻找 IP 地址的过程依次经过了浏览器缓存、系统缓存、hosts 文件、路由器缓存、 递归搜索根域名服务器(DNS解析)。
- 建立 TCP/IP 连接(三次握手)。
- 由浏览器发送一个 HTTP 请求。
- 经过路由器的转发,通过服务器的防火墙,该 HTTP 请求到达了服务器。
- 服务器处理该 HTTP 请求,返回一个 HTML 文件。
- 浏览器解析该 HTML 文件,并且显示在浏览器端。
- 服务器关闭 TCP 连接(四次挥手)。
https 协议中的 s 是什么?
SSL/TLS 安全套接字层,使得报文能够加密传输。TLS协议,是SSL 3.0协议的升级版
https 协议有什么缺点?
- HTTPS 协议多次握手,导致页面的加载时间延长近 50%;
- HTTPS 连接缓存不如 HTTP 高效,会增加数据开销和功耗;
- SSL 涉及到的安全算法会消耗 CPU 资源,对服务器资源消耗较大;
一次完整 HTTPS 建立连接所经历的步骤?
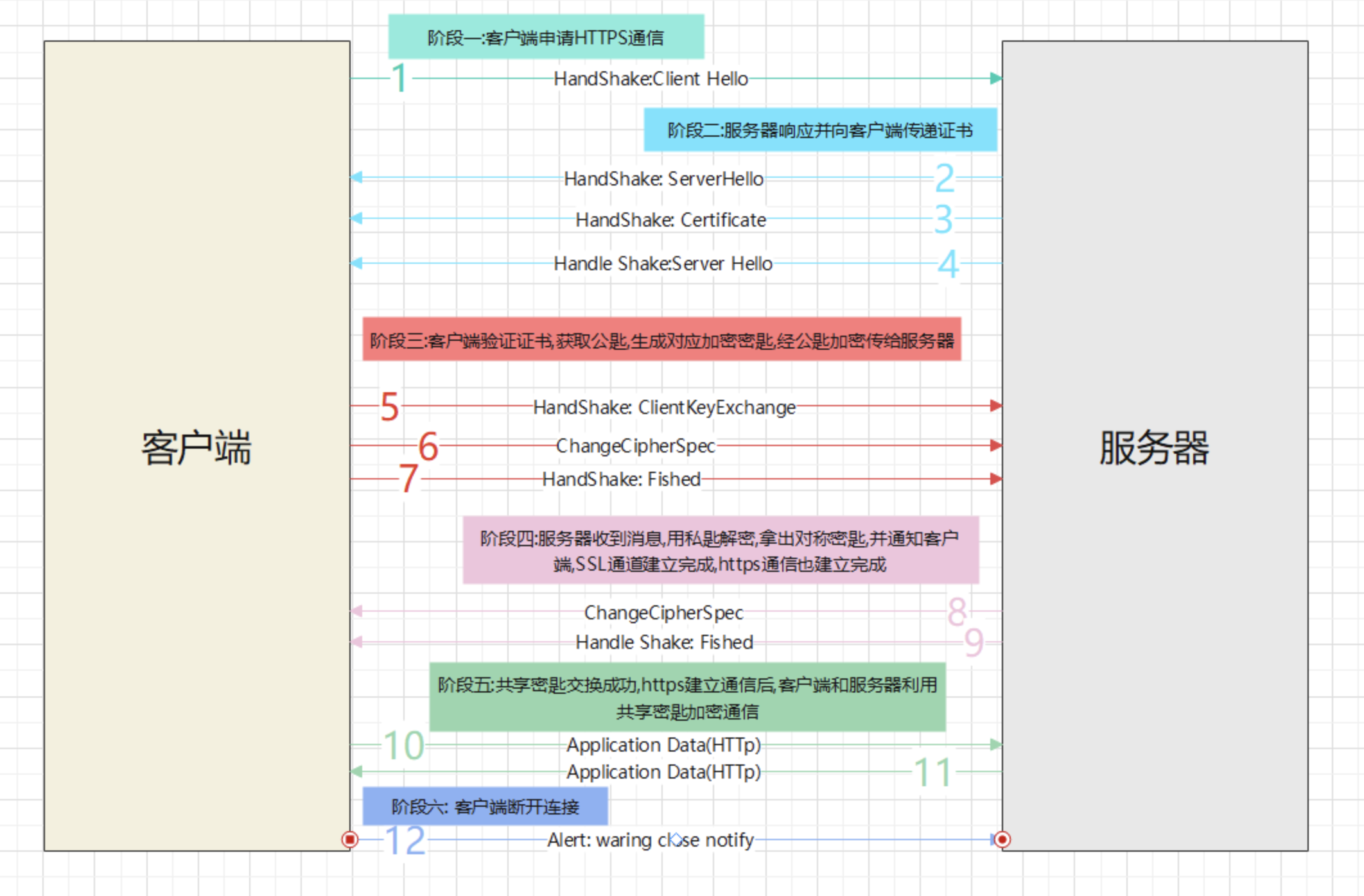
- 客户端 — Hello:客户端通过发送 Client Hello 报文开始 SSL 通信。报文中包含客户端支持的 SSL 的指定版本、加密组件(Cipher Suite)列表(所使用的加密算法及密匙长度等);
- 服务器 — Hello:服务器可进行 SSL 通信时,会以 Server Hello 报文作为应答。和客户端一样,在报文中包含 SSL 版本以及加密组件。服务器的加密组件内容是从接收到的客户端加密组件内筛选出来的;
- 服务器 — 发证书:服务器发送证书报文。报文中包含公开密匙证书;
- 服务器 — 我说完了:最后服务器发送 Server Hello Done 报文通知客户端,最初阶段的 SSL 握手协商部分结束;
- 客户端 — 发送秘钥:SSL 第一次握手结束之后,客户端以 Client Key Exchange 报文作为回应。报文包含通信加密中使用的一种被称为 Pre-master secret 的随机密码串。该报文已用步骤 3 中的公开密匙进行加密;
- 客户端 — 就用这个秘钥了:该报文会提示服务器,在此报文之后的通信会采用 Pre-master secret 密匙加密;
- 客户端 — 我说完了:该报文包含连接至今全部报文的整体校验值。这次握手协商是否能够成功,要以服务器是否能够正确解密该报文作为判定标准;
- 服务器 — 发送 c Change Cipher Spec 报文(我正在接收秘钥);
- 服务器 — 发送 d Finished 报文(我收完秘钥了);
- 客户端 — 开始发送正文:服务器端发送 HTTP 请求,发送相关内容;
- 服务器 — 开始接收正文:客户端接收 HTTP 请求,并处理相关内容;
- 客户端 — 断开链接:最后由客户端断开连接。断开连接时,发送 close_notify 报文。上图做了一些省略,这步之后再发送 TCP FIN 报文来关闭与 TCP 的通信;
https 密钥交换过程是什么?
- 服务端首先把自己的公钥Key1发给证书颁发机构,向证书颁发机构申请证书。
- 证书颁发机构自己也有一对公钥私钥。机构利用自己的私钥来加密Key1,并且通过服务端网址等信息生成一个证书签名,证书签名同样经过机构的私钥加密。证书制作完成后,机构把证书发送给了服务端。
- 当客户端向服务端请求通信的时候,服务端不再直接返回自己的公钥,而是把自己申请的证书返回给客户端。
- 客户端收到证书以后,第一件事情是验证证书的真伪。需要说明的是,各大浏览器和操作系统已经维护了所有权威证书机构的名称和公钥。所以客户端只需要知道是哪个机构颁布的证书,就可以从本地找到对应的机构公钥,解密出证书签名。
- 接下来,客户端按照同样的签名规则,自己也生成一个证书签名,如果两个签名一致,说明证书是有效的。验证成功后,客户端就可以放心地再次利用机构公钥,解密出服务端的公钥Key1。
- 客户端生成自己的对称加密密钥Key2,并且用服务端公钥Key1加密Key2,发送给服务端。
- 最后,服务端用自己的私钥解开加密,得到对称加密密钥Key2。于是两人开始用Key2进行对称加密的通信。
三次握手怎么理解?
- 客户端通过向服务器端发送一个SYN来创建一个主动打开,作为三次握手的一部分。客户端把这段连接的序号设定为随机数 A。
- 服务器端应当为一个合法的SYN回送一个SYN/ACK。ACK 的确认码应为 A+1,SYN/ACK 包本身又有一个随机序号 B。
- 客户端再发送一个ACK。当服务端受到这个ACK的时候,就完成了三路握手,并进入了连接创建状态。此时包序号被设定为收到的确认号 A+1,而响应则为 B+1。
为什么握手不是两次或者四次?
两次无法确认客户端的接收能力,四次可以但没必要。
三次握手过程中可以携带数据么?
第三次握手的时候,可以携带。前两次握手不能携带数据。
Client & Server 同时发送 SYN 会怎么样?
同时进行三次握手并处于ESTABLISHED状态
四次挥手怎么理解?
- 客户端发送一个数据分段, 其中的 FIN 标记设置为1. 客户端进入 FIN-WAIT 状态. 该状态下客户端只接收数据, 不再发送数据.
- 服务器接收到带有 FIN = 1 的数据分段, 发送带有 ACK = 1 的剩余数据分段, 确认收到客户端发来的 FIN 信息.
- 服务器等到所有数据传输结束, 向客户端发送一个带有 FIN = 1 的数据分段, 并进入 CLOSE-WAIT 状态, 等待客户端发来带有 ACK = 1 的确认报文.
- 客户端收到服务器发来带有 FIN = 1 的报文, 返回 ACK = 1 的报文确认, 为了防止服务器端未收到需要重发, 进入 TIME-WAIT 状态. 服务器接收到报文后关闭连接. 客户端等待 2MSL 后未收到回复, 则认为服务器成功关闭, 客户端关闭连接.
为什么挥手是四次而不是三次?如果是三次挥手会有什么问题?
服务端在接收到FIN, 必须等到服务端所有的报文都发送完毕了,才能发FIN。所以先发一个ACK表示已经收到客户端的FIN,延迟一段时间才发FIN 长时间的延迟可能会导致客户端误以为FIN没有到达客户端,从而让客户端不断的重发FIN。
TFO 了解嘛?说说它的原理,说说它的优势?
TCP Fast Open 快速打开
原理是:在首轮三次握手中服务端不立刻回复 SYN + ACK,而是通过计算得到一个SYN Cookie, 将这个Cookie放到 TCP 报文的 Fast Open选项中,然后才给客户端返回。
后面的三次握手客户端会将之前缓存的 Cookie、SYN 和HTTP请求发送给服务端,服务端验证了 Cookie 的合法性,可以在三次握手还没建立,仅仅验证了 Cookie 的合法性,就可以返回 HTTP 响应。 图解
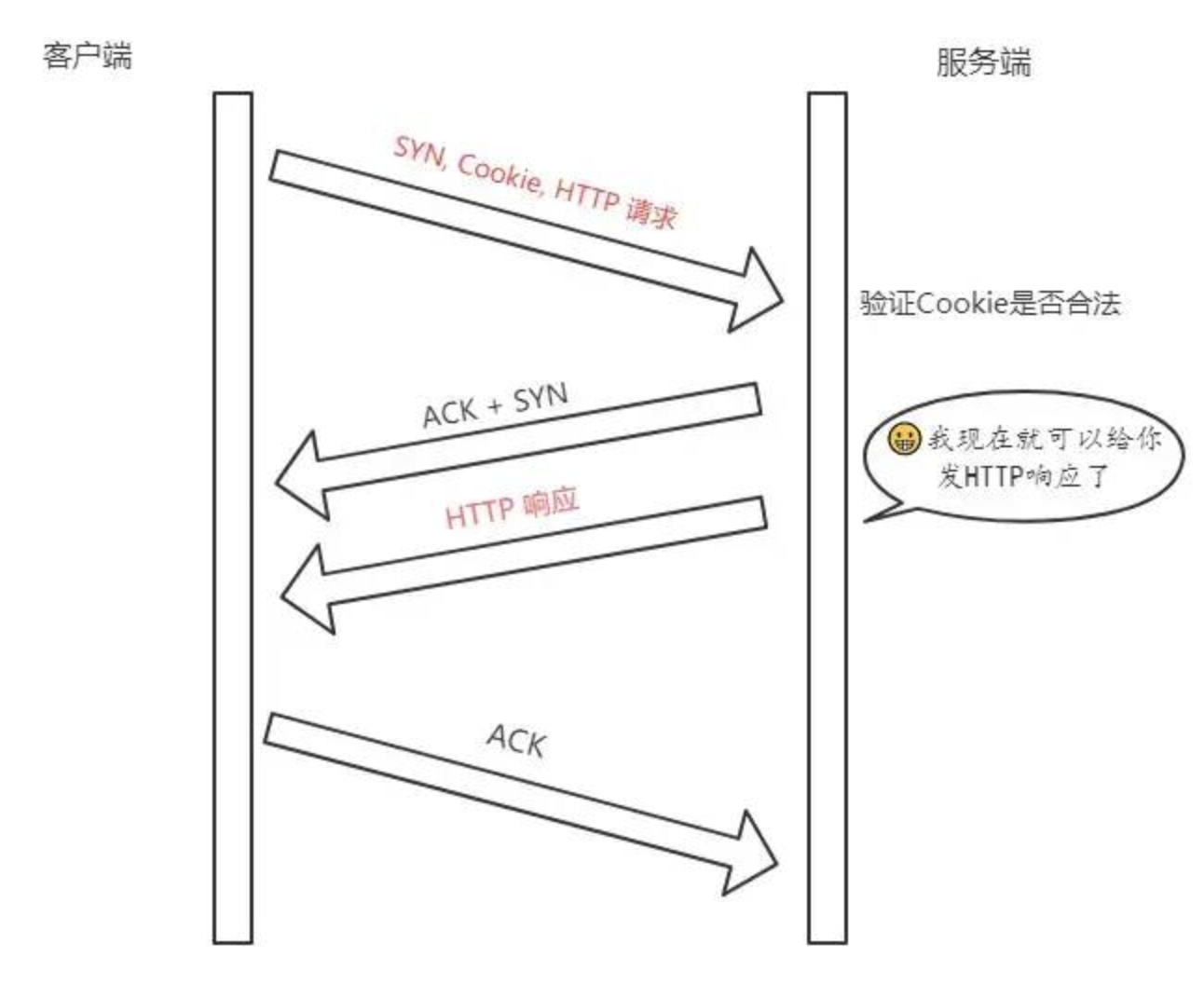
TFO 的优势在于后面的握手,直接返回 HTTP 响应,充分利用了1 个RTT(Round-Trip Time,往返时延)的时间提前进行数据传输
TCP 报文中时间戳有什么用?
计算往返时延 RTT
现代浏览器在与服务器建立了一个 TCP 连接后是否会在一个 HTTP 请求完成后断开?什么情况下会断开?
默认情况下建立 TCP 连接不会断开,只有在请求报头中声明 Connection: close 才会在请求完成后关闭连接。
一个 TCP 连接可以对应几个 HTTP 请求?
如果维持连接,一个 TCP 连接是可以发送多个 HTTP 请求的。
一个 TCP 连接中 HTTP 请求发送可以一起发送么(比如一起发三个请求,再三个响应一起接收)?
在 HTTP/1.1 是不可行的。在 HTTP/2 中多个 HTTP 请求可以在同一个 TCP 连接中并行进行
为什么有的时候刷新页面不需要重新建立 SSL 连接?
TCP 连接有的时候会被浏览器和服务端维持一段时间。TCP 不需要重新建立,SSL 自然也会用之前的。
浏览器对同一 Host 建立 TCP 连接到数量有没有限制?
Chrome 最多允许对同一个 Host 建立六个 TCP 连接。不同的浏览器有一些区别。
到的 HTML 如果包含几十个图片标签,这些图片是以什么方式、什么顺序、建立了多少连接、使用什么协议被下载下来的呢?
如果图片都是 HTTPS 连接并且在同一个域名下,那么浏览器在 SSL 握手之后会和服务器商量能不能用 HTTP2。
不过也未必会所有挂在这个域名的资源都会使用一个 TCP 连接去获取,但是可以确定的是很可能会用到多路复用。
如果用不了 HTTP2 只能使用 HTTP/1.1 那浏览器就会在一个 HOST 上建立多个 TCP 连接,连接数量的最大限制取决于浏览器设置,这些连接会在空闲的时候被浏览器用来发送新的请求,
如果所有的连接都正在发送请求,那其他的请求就只能等等了。
如何理解 TCP 的 keep-alive?
保活机制,本质是 TCP 协议层被动心跳探测机制
核心作用是在连接长时间无数据传输时,确认通信双方是否仍在线,避免无效连接占用服务器文件描述符、内存等资源,同时减少后续数据传输时的超时浪费。
keep-alive 和应用层心跳机制(如WebSocket 的 ping/pong)有什么区别?
-
keep-alive 只确认 “TCP 连接通不通”,无法感知应用进程是否崩溃
-
WebSocket 的 ping/pong 能直接确认 “应用是否正常”
二者常配合使用,前者保连接,后者保服务。
域名带 www 与不带 www 有何区别?
- DNS 解析类型限制不同。带 www(子域名)支持 CNAME 解析。
- 服务器配置不同。二者分别都是完全独立的域名实体。
- 资源与归属不同。cookie 默认不互通(需要手动配置主语子域共享),搜索引擎会把二者视为独立的 URL(需要配置 301 重定向)。
怎么理解 rpc?
Remote Procedure Call 远程过程调用
已经有 http 服务了为什么还有 rpc 服务?
因为良好的rpc调用是面向服务的封装,针对服务的可用性和效率等都做了优化。单纯使用http调用则缺少了这些特性。
其实是先有的 rpc 再有的 http 前者是基于 C/S 架构实现的后者是基于 B/S架构实现的 RPC 只是一种调用方式 thrift 基于 TCP 而 gRPC 基于 HTTP/2 但是也可以基于 UDP 或 HTTP 实现
RPC效率更高,而HTTP服务开发迭代会更快。
RPC 调用和 HTTP 调用的区别( HTTP and RPC )
数据库
redis 和 memcache 有什么区别?使用场景
- redis和Memcache都是将数据存放在内存中,都是内存数据库。不过memcache还可以用于缓存其他东西,例如图片,视频等等
- Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,hash等数据结构的存储
- 虚拟内存-redis当物流内存用完时,可以将一些很久没用的value交换到磁盘
- 过期策略-memcache在set时就指定,例如set key1 0 0 8,即永不过期。Redis可以通过例如expire设定,例如expire name 10
- 分布式-设定memcache集群,利用magent做一主多从,redis可以做一主多从。都可以一主一丛
- 存储数据安全-memcache挂掉后,数据没了,redis可以定期保存到磁盘(持久化)
- 灾难恢复-memcache挂掉后,数据不可恢复,redis数据丢失后可以通过aof恢复
- Redis支持数据的备份,即master-slave模式的数据备份
- 应用场景不一样,redis除了作为NoSQL数据库使用外,还能用做消息队列,数据堆栈和数据缓存等;Memcache适合于缓存SQL语句,数据集,用户临时性数据,延迟查询数据和session等
使用场景:
- 如果有持久方面的需求或对数据类型和处理有要求的应该选择redis
- 如果简单的key/value存储应该选择memcached.
redis 和 MySQL 有什么区别?
- redis 是内存数据库,数据保存在内存中,速度快。
- mysql 是关系型数据库,持久化存储,存放在磁盘里面,功能强大。检索的话,会涉及到一定的 IO,数据访问也就慢。
- 需要永久存储的数据使用MySQL,比如用户信息,文章等
- 而临时数据或者经常访问的数据就会使用redis,比如用户的session/排行榜/访问计数/Pub Sub 构建实时消息系统/缓存等
redis 的几种数据结构了解吗?
string、set、zset、hash、list
redis 为什么快?除了基于内存操作还有其他原因吗?
- I/O 多路复用,事件处理器处理事件(这个可以理解为注册的一段函数,定义了事件发生的时候应该执行的动作), 这里分派事件和处理事件其实都是同一个线程;
- 纯内存操作效率高,查找和操作的时间复杂度都是O(1);
- 单线程反而避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗。
介绍一下 I/O 多路复用的流程?
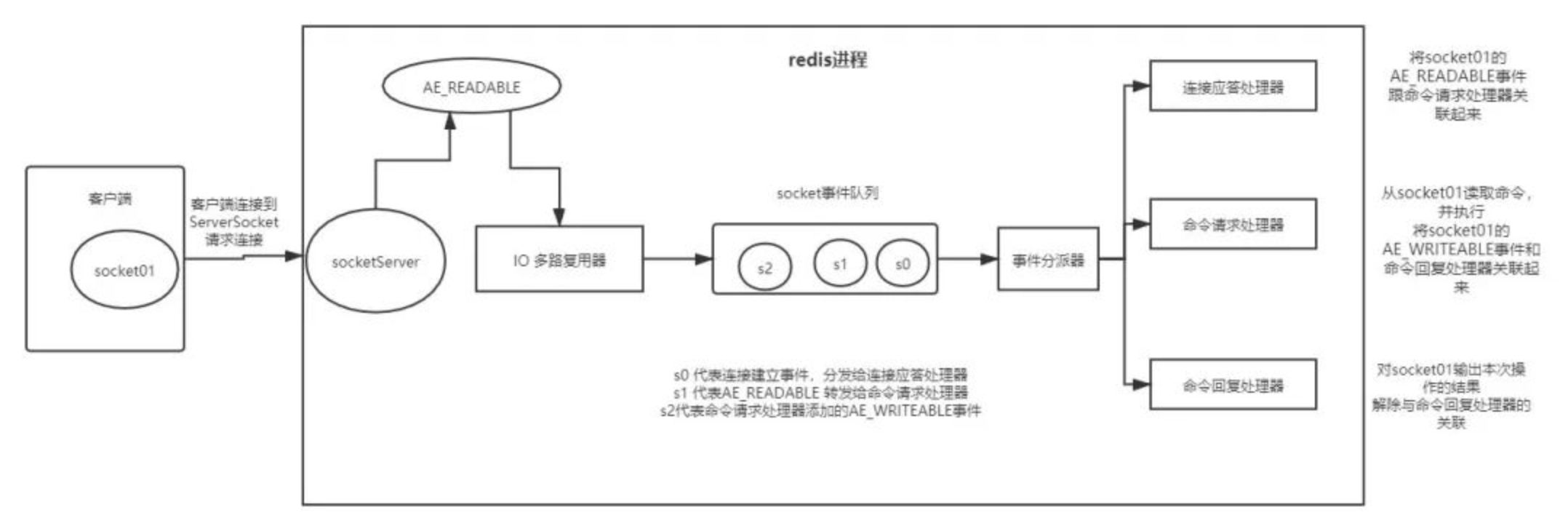
- 首先接收到客户端的 socket 请求,多路复用器将 socket 转给连接应答处理器;
- 连接应答处理器将 AE_READABLE 事件与命令请求处理器关联(这里是把 socket 事件放入一个队列);
- 命令请求处理器从 socket 中读到指令,再内存中执行,并将 AE_WRITEABLE 事件与命令回复处理器关联;
- 命令回复处理器将结果返回给 socket,并解除关联。
redis 的内存管理机制与gc?
-
定期删除+惰性删除
- 主动过期(定期删除):默认每 100ms 随机抽取一些设置了过期事件的 key 检查是否过期,如果过期就删除。如果 10w 个 key 都设置了过期时间,全部检查会增高 CPU 负载。
- 被动过期(惰性删除):key 被访问时,如果发现它已经过期就删除。
-
最大内存淘汰( redis 内存占用太多,就会进行内存淘汰)
- noeviction: 如果内存不足以写入数据, 新写入操作直接报错;
- allkeys-lru: 内存不足以写入数据,移除最近最少使用的 key(最常用的策略);
- allkeys-random: 内存不足随机移除几个 key;
- volatile-lru: 在设置了过期时间的 key 中,移除最近最少使用;
- volatile-random: 设置了过期的时间的 key 中,随机移除几个。
Redis是单线程还是多线程?
Redis 中只有网络请求模块和数据操作模块是单线程的。而其他的如持久化存储模块、集群支撑模块等是多线程的。
Redis是单线程的,如何提高多核CPU的利用率?
- 多实例部署。在同一台服务器启动多个独立 Redis 实例(用不同端口、配置文件隔离),让 OS 将实例调度到不同 CPU 核心。
- 利用多线程特性。将网络请求拆分到独立线程,核心单线程仅负责 “命令解析与执行”,解决大流量 IO 瓶颈。
- 架构优化。多服务器集群将实例分散到多台机器的多核上。
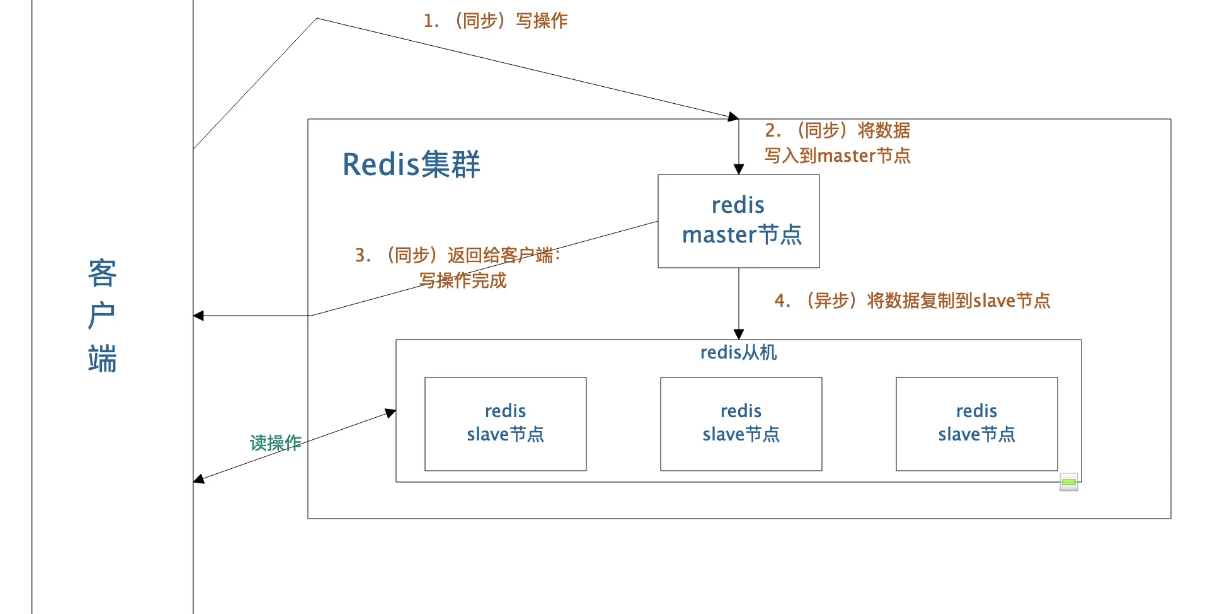
redis 如何保证高并发场景?
读写分离保证高并发(10W+ QPS):对于缓存来说一般都是支撑高并发读,写请求都是比较少的。master 负责接收写请求,数据同步到 slave 上提供读服务,增加 slave 机器就可以水平扩容。
redis 哨兵有了解吗?是干什么的有什么特性?
哨兵是 redis 集群架构的一个重要组件,主要提供功能:集群监控、消息通知、故障转移、配置中心 哨兵至少三个,保证自己的高可用;
哨兵+主从的部署架构是用来保证 redis 集群高可用的,并非保证数据不丢失;
哨兵(Sentinel)需要通过不断的测试和观察才能保证高可用
为什么哨兵至少是 3 个,2 个不可以吗?
满足 majority 才可以允许故障转移执行。2 个哨兵的 majority 是 2,如果 2 个哨兵都运行着就允许执行故障转移。如果 M1 所在的机器宕机了,那么 s1 哨兵也就挂了,只剩 s2 一个,
没有 majorityl 来允许执行故障转移,虽然集群还有一台机器 R1,但是故障转移也不会执行。
用 redis 来实现限制一个api或页面访问的频率,例如单ip或单用户一分钟之内只能访问多少次?
在redis中保存一个count值(int),key为user:$ip,value为该ip访问的次数,第一次设置key的时候,设置expires。
count加1之前,判断是否key是否存在,不存在的话,有两种情况:1、该ip未访问过;2、该ip访问过,但是key已经过期了。那么此时需要再次设置一次expires。如果用户访问的时候,判断count的值是否大于上限,如果低于上限,就处理请求,否则就拒绝处理请求。
# 考虑这种情况,假设只允许用户60秒内访问100次,如果有一个用户在第1秒访问了1次,在第59秒的时候,访问了99次,然后在第61秒的时候,访问了100次。如果按照策略1的情况处理,第1~60秒之间接受了100次,在第61秒接收100次请求,所以62~120这段时间内,不再处理该ip的请求。
# 貌似没问题,但是,细细思考一下,第59秒到61秒之间接受了99+100=199请求,时间间隔只有3秒。那么这样的话,最初的设计就存在问题了。
解决方案:可以使用redis的list(双向队列)数据结构,key就是user:$ip,也就是每一个ip设置一个双向队列,每次请求到达的时候,进行如下判断:
1、如果list中的元素个数少于100个,那么就将请求到达时的时间戳Lpush到list中。
2、如果list中的元素多余100个,那么,就取出Lindex(-1)即最右边,也就是100个请求中最早的那一个请求的时间戳,如果最早的时间戳和当前时间戳相差超过60秒,那么表示第一个请求已经过期了,就将第一个请求出队Rpop。然后将当前时间戳入队Lpush
什么是索引?
索引是一种单独的,物理的对数据库表中一列或者多列的值进行排序的一种存储结构。
相当于图书的目录,可以根据目录中的页码快速找到需要的内容
什么是联合索引?
通过第一个字段的值(部首)在第一级索引中找到对应的第二级索引位置(检字表页码)
然后在第二级索引中根据第二个字段的值(笔画)找到符合条件的数据所在的位置(某个字的真正页码)。
什么是聚集索引、非聚集索引、覆盖索引?
像拼音目录这样的索引,数据会根据索引中的顺序进行排列和组织的,这样的索引就被称为聚集索引,而非聚集索引就是其他的一般索引。因为数据只能按照一种规则排序,所以一张表至多有一个聚集索引,但可以有多个非聚集索引
https://zhuanlan.zhihu.com/p/476444902
给你ab,ac,abc字段,你是如何加索引的?
加abc联合索引和ac联合索引。
这个最左前缀可以是联合索引的最左N个字段。比如组合索引(a,b,c)可以相当于建了(a),(a,b),(a,b,c)三个索引,大大提高了索引复用能力。
最左前缀也可以是字符串索引的最左M个字符。
索引可以创建多少列?
16 列
什么是视图?视图的使用场景有哪些?
视图是一种虚拟的表,具有和物理表相同的功能,只暴露部分字段给访问者,所以就建一个虚表,就是视图。
查询的数据来源于不同的表,而查询者希望以统一的方式查询,这样也可以建立一个视图,把多个表查询结果联合起来,查询者只需要直接从视图中获取数据,不必考虑数据来源于不同表所带来的差异
视图的作用是什么?
- 数据库视图隐藏了数据的复杂性。
- 数据库视图有利于控制用户对表中某些列的访问。
- 数据库视图使用户查询变得简单。
事务的特性有哪些?
- 原子性(Atomicity):事务中的全部操作在数据库中是不可分割的,要么全部完成,要么均不执行。
- 一致性(Consistency):几个并行执行的事务,其执行结果必须与按某一顺序串行执行的结果相一致。
- 隔离性(Isolation):事务的执行不受其他事务的干扰,事务执行的中间结果对其他事务必须是透明的。
- 持久性(Durability):对于任意已交事务,系统必须保证该事务对数据库的改变不被丢失。
主键(primary key)和候选键(candidate key)有什么区别?
- 候选键 - 候选键可以是任何列或可以作为数据库中唯一键的列组合。一张表中可以有多个候选键。每个候选键都可以作为主键。
- 主键 - 主键是唯一标识记录的列或列组合。只有一个候选键可以是主键。
主键和唯一键有什么区别?
两者都用于强制定义的列的唯一性,但主键会创建聚集索引,而唯一键会在列上创建非聚集索引。主键不允许’NULL’,但唯一键允许它。
数据库怎么优化查询效率?
- 避免模糊查询,如OR、LIKE等,因为会导致全表扫描;
- 在常用字段加索引,例如WHERE、JOIN ON和ORDER BY使用到字段上应该加索引
- 尽量避免全局性的读写操作,例如SELECT * 、Update全部字段
了解数据库优化方案有哪些?
- 优化索引、SQL 语句、分析慢查询;
- 设计表的时候严格根据数据库的设计范式来设计数据库;
- 使用缓存,把经常访问到的数据而且不需要经常变化的 数据放在缓存中,能节约磁盘 IO;
- 优化硬件;采用 SSD,使用磁盘队列技术 (RAID0,RAID1,RDID5)等;
- 采用 MySQL 内部自带的表分区技术,把数据分层不同 的文件,能够提高磁盘的读取效率;
- 垂直分表;把一些不经常读的数据放在一张表里,节约 磁盘 I/O;
- 主从分离读写;采用主从复制把数据库的读操作和写入操作分离开来;
- 分库分表分机器(数据量特别大),主要的的原理就是数据路由;
- 选择合适的表引擎,参数上的优化;
- 进行架构级别的缓存,静态化和分布式;
- 不采用全文索引;
- 采用更快的存储方式,例如 NoSQL 存储经常访问的数
写一条 SQL 最重要的是什么?
命中索引
千万级数据如何自动化并频繁写入 MySQL?
pandas + sqlalchemy:pandas在sqlalchemy的支持下,可以实现所有常见数据库类型的查询、更新等操作
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://root:xuyuanzhe@localhost:3306/test01')
data = pd.read_csv('./tianchi_mobile_recommend_train_user.csv')
data.to_sql('user02',engine,chunksize=100000,index=None)
print('success')
如何将数据从一张表复制到另一张表?
INSERT INTO table2 (id,uid,changed,status,assign_status) SELECT id,uid,now(),'Pending','Assigned' FROM table1
如何在不复制数据的情况下复制表?
CREATE TABLE users_bck SELECT * FROM users WHERE 1=0;
MySQL 的底层数据结构是什么?
B+树
MySQL 的两种引擎是什么?
InnoDB 和 MyISAM
InnoDB 支持事务,MyISAM 不支持事务
InnoDB 支持外键,MyISAM 不支持
InnoDB 是聚集索引,MyISAM 是非聚集索引
MySQL锁有几种?
- 表锁。MyISAM 引擎默认,DDL(如 ALTER TABLE)、LOCK TABLES 显式加锁。
- 行锁。InnoDB 引擎默认,基于索引加锁(无索引会退化为表锁)。
- 共享锁。读操作加,多事务可共享,互斥写锁。
- 排他锁。写操作加,排斥所有其他锁(S/X)。
死锁是怎么产生的?
死锁产生需同时满足 4 个必要条件:
- 资源互斥:资源同一时间只能被一个进程 / 事务占用(如 MySQL 行锁、文件独占锁);
- 持有并等待:进程持有已获资源,同时等待其他资源,且不释放已持资源;
- 不可剥夺:资源只能由持有进程主动释放,无法被强制剥夺(如 MySQL 事务未提交 / 回滚,行锁不会被抢);
- 循环等待:多个进程形成闭环等待链(如 A 等 B 的资源,B 等 C 的资源,C 等 A 的资源)。
char varchar text 有何区别?
- char是一种固定长度的类型,每个值都占用N个字节,如果某个长度小于N,MySQL就会在它的右边用空格字符补足。合适存储具有近似得长度(md5值,身份证,手机号),长度比较短小的字符串。
- varchar则是一种可变长度的类型,每个值只占用刚好够用的字节再加上一个用来记录其长度的字节。适合经常更新得字符串,更新时不会出现页分裂得情况,避免出现存储碎片,获得更好的io性能。
区分 FLOAT 和 DOUBLE?
- 浮点数以八位精度存储在 FLOAT 中,它有四个字节。
- 浮点数以 18 位精度存储在 DOUBLE 中,它有 8 个字节。
了解join么,有几种,有何区别?
- INNER JOIN 内连接。只保留 A、B 中匹配条件(ON 子句)的行,不匹配的行全部过滤。
- A 存用户,B 存订单,INNER JOIN 只查 “有订单的用户” 和 “有对应用户的订单”。
- LEFT JOIN 左连接。保留 左表 A 的所有行,右表 B 只保留匹配行;B 中不匹配的列补 NULL。
- 查 “所有用户”,即使无订单的用户也显示,订单列填 NULL。
- RIGHT JOIN 右连接。与 LEFT JOIN 相反,保留 右表 B 的所有行,左表 A 只保留匹配行;A 中不匹配的列补 NULL。
- 查 “所有订单”,即使订单对应的用户已删除(A 中无记录),用户列填 NULL。
- FULL JOIN 全连接。保留 A、B 所有行,双方不匹配的列分别补 NULL。
- MySQL 需用 LEFT JOIN + UNION + RIGHT JOIN 模拟(UNION 去重)。
- CROSS JOIN 交叉连接。无 ON 条件时,A 的每一行与 B 的每一行强制匹配,结果行数 = A 行数 × B 行数。
- 若加 ON 条件,等同于 INNER JOIN;慎用(数据量易爆炸)。
NOW() 和 CURRENT_DATE() 有什么区别?
- NOW () 命令用于以小时、分钟和秒显示当前年、月、日。
- CURRENT_DATE() 仅显示当前年、月和日期。
MySQL 表中允许多少个触发器?
- 插入前
- 插入后
- 更新前
- 更新后
- 删除前
- 删除后
为何,以及如何分区、分表;
核心目的是解决单表数据量过大导致的性能瓶颈。中小规模用分区(简单),超大规模 + 高并发用分表(灵活扩展),或二者结合(如先分表再分区)。
分区:单表逻辑拆分,物理存储分离(MySQL 内置功能)
- 范围分区(RANGE)
- 按连续范围拆分,如订单表按 create_time 分区。
- 适合时间序列数据,可快速删除历史分区。
- 列表分区(LIST)
- 按离散值拆分,如按 region_id 分区存储不同地区数据。
- 哈希分区(HASH)
- 按字段哈希值均匀分布数据,适合无明显范围特征的场景(如按用户 ID 分区)。
分表:将大表拆分为多个独立小表(逻辑 / 物理拆分)
- 水平分表(按行拆分,最常用)
- 按规则将数据分散到多个表(表结构相同),如:
- 范围分表:按时间(如 order_2023、order_2024)、ID 范围(user_1 存 ID 1-100 万,user_2 存 101 万 - 200 万);
- 哈希分表:按 ID 哈希取模(user_{id%10} 分 10 张表)。
- 实现:需业务层路由(如 Sharding-JDBC),或中间件自动转发。
- 按规则将数据分散到多个表(表结构相同),如:
- 垂直分表(按列拆分)
- 将大宽表按 “访问频率” 拆分,如用户表拆为 user_base(基本信息,高频访问)和 user_extra(详细信息,低频访问),减少单表字段数,提升查询效率。
关系型数据库和非关系型数据库?
- 数据与结构:RDBMS 是 “表结构 + 预定义 Schema”,NoSQL 是 “键值 / 文档等灵活模型”,无需固定结构;
- 事务与扩展:RDBMS 强支持 ACID 事务,水平扩展复杂;NoSQL 多弱事务,天然支持水平扩容;
- 场景适配:RDBMS 用在数据固定、需强一致性(如订单、财务);NoSQL 用在海量非结构化数据、高并发(如缓存、日志)。
MongoDB的底层数据结构是什么?
B树
操作系统
怎么理解同步异步?
同步和异步关注的是消息通信机制:
- 同步,就是在发出一个调用时,在没有得到结果之前,该调用就不返回;
- 异步则是相反,调用在发出之后,这个调用就直接返回了,所以没有返回结果。
举例:
- 你打电话问书店老板有没有《分布式系统》这本书,如果是同步通信机制,书店老板会说,你稍等,”我查一下”,然后开始查啊查,等查好了(可能是5秒,也可能是一天)告诉你结果(返回结果)。
- 而异步通信机制,书店老板直接告诉你我查一下啊,查好了打电话给你,然后直接挂电话了(不返回结果)。然后查好了,他会主动打电话给你。在这里老板通过“回电”这种方式来回调。
怎么理解阻塞非阻塞?
阻塞和非阻塞关注的是程序在等待调用结果(消息,返回值)时的状态:
- 阻塞调用是指调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才会返回;
非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前线程。 - 你打电话问书店老板有没有《分布式系统》这本书,你如果是阻塞式调用,你会一直把自己“挂起”,直到得到这本书有没有的结果,如果是非阻塞式调用,你不管老板有没有告诉你,你自己先一边去玩了, 当然你也要偶尔过几分钟check一下老板有没有返回结果。
在这里阻塞与非阻塞与是否同步异步无关。跟老板通过什么方式回答你结果无关
什么是僵尸进程和孤儿进程?怎么避免僵尸进程?
- 孤儿进程: 父进程退出,子进程还在运行的这些子进程都是孤儿进程,孤儿进程将被init 进程(进程号为1)所收养,并由init 进程对他们完成状态收集工作。
- 僵尸进程: 进程使用fork 创建子进程,如果子进程退出,而父进程并没有调用wait 获waitpid 获取子进程的状态信息,那么子进程的进程描述符仍然保存在系统中的这些进程是僵尸进程。
避免僵尸进程的方法:
- fork 两次用孙子进程去完成子进程的任务
- 用wait()函数使父进程阻塞
- 使用信号量,在signal handler 中调用waitpid,这样父进程不用阻塞
什么是虚拟内存?
虚拟内存则是虚拟出来的、使用磁盘代替内存。memory就是机器的物理内存,读写速度低于cpu一个量级,但是高于磁盘不止一个量级。
所以,程序和数据如果在内存的话,会有非常快的读写速度。内存的断电丢失数据是一个不能把所有数据和程序都保存在内存中对原因。
当内存没有可用的,就必须要把内存中不经常运行的程序给踢出去。但是踢到哪里去,这时候swap就出现了。
swap全称为swap place,即交换区,当内存不够的时候,被踢出的进程被暂时存储到交换区。当需要这条被踢出的进程的时候,就从交换区重新加载到内存,否则它不会主动交换到真实内存中。
正则
search和match的区别?
- match() 函数只检测字符串开头位置是否匹配,匹配成功才会返回结果,否则返回None;
- search() 函数会在整个字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。
正则匹配 <.*> 和 <.*?> 分别对 <h1>title</h1> 进行正则匹配输出什么?
前者匹配 <h1>title</h1> ,后者匹配 <h1>
正则匹配里的 * 和 + 有什么区别?
前者匹配零次或多次,后者匹配一次或多次
如何提高正则的可读性?
加注释
import re
msg = '我叫xxx,我的密码是:123kingname456,请注意保密。'
pattern = '''
: # 开始标志
(.*?) #从开始标志的下一个字符开始的任意字符
, #遇到英文逗号就停止
'''
re.findall(pattern, msg, flags=re.X)
爬虫
网站如何监测爬虫使用了代理?
- 根本没有使用代理,
proxies={'http': 'http://IP:port', 'https': 'http://IP:port'}给https网址设置代理的时候,key是https,但值依然是http:// - 代理IP是服务器IP,云服务器IP范围是公开的
- 代理IP不是高匿代理,区分透明代理、匿名代理、高匿代理
- 服务器供应商的IP池被污染,垃圾爬虫和你使用了同一家代理
- 代理不支持HTTP/2,大部分供应商提供的还是HTTP/1.1的代理
在 App 逆向中常见的加密算法有哪些?
- 消息摘要算法(散列函数、哈希函数) MD5、SHA、MAC
- 对称加密算法 DES、3DES、AES
- 非对称加密算法 RSA
- 数字签名算法 MD5withRSA、SHA1withRSA、SHA256withRSA
Golang
byte 和 uint8 是什么关系?
等价关系 byte 也属于无符号整型类型
Python
对面向对象的理解?
面向对象是相当于面向过程而言的,面向过程语言是一种基于功能分析的,以算法为中心的程序设计方法,而面向对象是一种基于结构分析的,以数据为中心的程序设计思想。
在面向对象语言中有一个很重要的东西,叫做类。面向对象有三大特性:封装、继承、多态。
python 一切皆对象怎么理解?
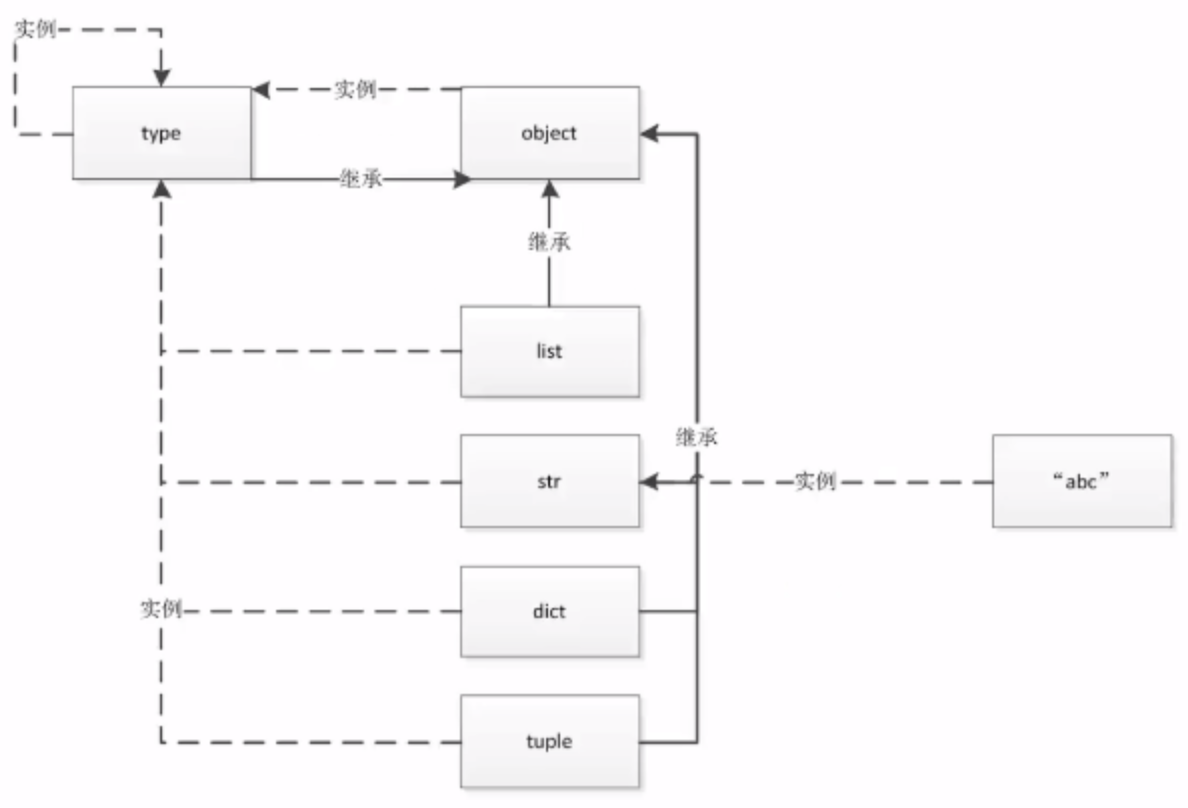
type 类实例化了 object ,type 类由继承自 object,这不矛盾。无论是 type,还是 object,它们即是对象,也是类,所以既拥有对象的特性,也拥有类的特性。
type 掌管了对象的特性,object 掌管了类的特性,所以两者相互依存。我们 用一幅图来说明,如下图所示,虚线表示对象实例化生成关系,实线表示类的继承关系。
所有类都拥有对象的特信息,所以都由type实例化生成,所有对象都拥有类的特性,所以都继承自 object。
什么是类?
类是模板,而实例则是根据类创建的对象。
使用类的对象,我们可以访问类的所有成员,并对其进行操作。
什么是元类?
实例对象是由类来创建,类是由元类来创建的。python的类都是由 type 类继承的,可以想象为元类是一个类的父类。在Django中多用元类创建语法糖。
Python MetaClass Notes
解释以下什么是闭包?
在函数内部再定义一个函数,并且这个函数用到了外边函数的变量,那么将这个函数以及用到的一些变量称之为闭包。
Python 的装饰器怎么理解?内部实现原理?
装饰器本质上是一个 callable object,是闭包的一种实现, 它的作用是让其他函数在不需要做任何代码变动的前提下增加额外功能。
使用装饰器的时候, 解析器把被装饰的函数作为参数传递给装饰器, 然后再返回一个函数对象, 装饰器内部实现需要额外增加的功能和被装饰函数的功能,虽然被装饰函数的调用方法没有改变, 但实际上已经不是原来函数, 而变成了装饰器返回的函数对象
它经常用于有切面需求的场景,比如:插入日志、性能测试、事务处理、缓存、权限校验等场景。
Python 什么时候执行装饰器?
函数装饰器在导⼊模块时⽴即执⾏,⽽被装饰的函数只在明确调⽤时运⾏。这突出 了Python程序员所说的导⼊时和运⾏时之间的区别。
什么是面向切面编程AOP?
在运行时,动态地将代码切入到类的指定方法、指定位置上的编程思想就是面向切面的编程。
手写一个普通装饰器,一个带参装饰器?
import functools
# 普通装饰器
def decorator(fn):
context = 1
@functools.wraps(fn)
def wrapper(*args, **kwargs):
print("context", context)
return fn(*args, **kwargs)
return wrapper
@decorator
def func():
print("I am target")
func()
#带参数的装饰器
def decorator_out(context):
def decorator(fn):
@functools.wraps(fn)
def wrapper(*args, **kwargs):
print("context", context)
return fn(*args, **kwargs)
return wrapper
return decorator
@decorator_out(3)
def test(*args, **kwargs):
print(1)
test()
装饰器有哪些实用的场景?
- 日志记录:自动记函数调用信息
- 性能测试:测函数执行时间
- 权限验证:先验证权限再执行函数
- 参数校验:确保参数符合要求
- 结果缓存:重复调用不重复计算
@staticmethod & @classmethod 有何区别?
Python 有 3 个方法,静态方法,类方法,实例方法
- 类方法: 是类对象的方法,在定义时需要在上方使用 @classmethod 进行装饰,形参为cls,表示类对象,类对象和实例对象都可调用
- 类实例方法: 是类实例化对象的方法,只有实例对象可以调用,形参为self,指代对象本身;
- 静态方法: 是一个任意函数,在其上方使用 @staticmethod 进行装饰,可以用对象直接调用,静态方法实际上跟该类没有太大关系
def foo(x):
print("executing foo(%s)" % x)
class A(object):
# 实例方法
def foo(self, x):
print("executing foo(%s,%s)" % (self, x))
# 类方法
@classmethod
def class_foo(cls,x):
print("executing class_foo(%s,%s)" % (cls, x))
# 静态方法
@staticmethod
def static_foo(x):
print("executing static_foo(%s)" % x)
a = A()
| \ | 实例方法 | 类方法 | 静态方法 |
|---|---|---|---|
| a = A() | a.foo(x) | a.class_foo(x) | a.static_foo(x) |
| A | 不可用 | A.class_foo(x) | A.static_foo(x) |
解释一下实例方法中的 self
在类里每次定义方法的时候都需要绑定实例,也就是foo(self, x)
因为实例方法的调用离不开实例,我们需要把实例自己传给函数,调用的时候是这样的 a.foo(x) 但其实是foo(a, x)
魔术方法的双下划线意义何在?
只是一种约定,Python 内部的名字,用来区别其他用户自定义的命名,以防冲突
hasattr() getattr() setattr() 函数使用详解?
- hasattr(object,name): 判断一个对象里面是否有 name 属性或者 name 方法,返回bool值,有name属性(方法)返回True,否则返回False。
- getattr(object, name, [default]): 获取对象object的属性或者方法,如果存在则打印出来,如果不存在,打印默认值,默认值可选。
- setattr(object, name, values): 给对象的属性赋值,若属性不存在,先创建再赋值
class function_demo(object):
name = "demo"
def run(self):
return "hello function"
functiondemo = function_demo()
res = hasattr(functiondemo, "addr") # 先判断是否存在
if res:
addr = getattr(functiondemo, "addr")
print(addr)
else:
addr = getattr(functiondemo, "addr", setattr(functiondemo, "addr", "北京首都"))
print(addr)
将列表生成式中 [] 改成 () 之后数据结构是否改变?
是,从列表变为生成器
iterator & generator
可迭代的对象的意思是就是说这个实体是可迭代的,例如字符、列表、元组、字典、迭代器等等,可以用for … in进行循环,可以使用for循环迭代的标志是内部实现了__iter__方法。
在 py2 中 range 和 xrange 前者返回list后者返回的是一个生成器,不会一下子开辟出所有的内存空间,边循环,边计算。
生成器和迭代器的区别?
生成器是一种特殊的迭代器,由 yield 关键字创建,自动实现迭代器协议;迭代器是实现了iter() 和next() 方法的对象,范围更广泛,生成器是迭代器的子集
解释一下 yield 的用法
yield就是保存当前程序执行状态。你用for循环的时候,每次取一个元素的时候就会计算一次,它允许函数在执行过程中暂停并返回一个值,同时保留函数的状态,以便下次调用时可以从上次暂停的地方继续执行。用yield 的函数叫generator,和iterator一样,它的好处是不用一次计算所有元素,而是用一次算一次,可以节 省很多空间,generator每次计算需要上一次计算结果,所以用yield,否则一return,上次计算结果就没 了
new & init
前者可以决定是否调用后者,可以决定调用哪个类的init方法。
-
__new__是一个静态方法,而__init__是一个实例方法. -
__new__方法会返回一个创建的实例,而__init__什么都不返回. - 只有在
__new__返回一个cls的实例时后面的__init__才能被调用. - 当创建一个新实例时调用
__new__,初始化一个实例时用__init__.
enter & exit
with方法帮助实现了一个 __enter__ 和 __exit__ 的方法。读取和退出的时候自动调用,在操作文件或网络的异步操作的时候很有用。
打开一个超大的 JSON 文件用 with 方法好吗?为什么不好?
不好,将整个JSON文件直接加载到内存中是一种内存浪费。 每个字符串都有固定的开销,如果字符串可以表示为 ASCII,则每个字符只使用一个字节的内存。如果字符串使用更多扩展字符,则每个字符可能使用4个字节
简述read、readline、readlines的区别?
- read 读取整个文件
- readline 读取下一行
- readlines 读取整个文件到一个迭代器以供我们遍历
现在要处理一个大小为 10G 的文件,但是内存只有4G,应该如何实现?需要考虑的问题都有那些?
def get_lines():
with open('file.txt','rb') as f:
for i in f:
yield i
要考虑的问题有:内存只有4G无法一次性读入10G文件,需要分批读入数据要记录每次读入数据的位置。分批每次读取数据的大小,太小会在读取操作花费过多时间。
https://stackoverflow.com/questions/30294146/python-fastest-way-to-process-large-file
如何查看一个对象的内存?
sys.getsizeof()
怎么做更好?
流解析,或者说是惰性解析、迭代解析或分块处理,比如使用 ijson pandas SQLite
Python 代码是怎样执行的?
首先,解释器读取Python代码并检查是否有语法或格式错误。
如果发现错误,则暂停执行。如果没有发现错误,则解释器会将Python代码转换为等效形式或字节代码。
然后将字节码发送到Python虚拟机(PVM),这里Python代码将被执行,如果发现任何错误,则暂停执行,否则结果将显示在输出窗口中。
Python 中可变对象和不可变对象是什么?
- 可变对象(Mutable):对象创建后,内容可以修改,内存地址不变
- 不可变对象(Immutable):对象创建后无法修改,修改会创建新对象
不可变对象(int, float, str, tuple, bool)可理解为C中,该参数为值传递
可变对象(list, dict, set, bytearray)可理解为C中,该参数为指针传递
如何判断一个对象是否可变?
判断是否可哈希(不可哈希的一定是可变的)
try:
hash(obj)
print("可能是不可变对象")
except TypeError:
print("是可变对象")
is和==有什么区别?
- is:比较的是两个对象的id值是否相等,也就是比较俩对象是否为同一个实例对象。是否指向同一个内存地址
- == : 比较的两个对象的内容/值是否相等,默认会调用对象的eq()方法
什么是深拷贝?什么是浅拷贝?
- 浅拷贝:创建新对象,但复制元素的引用
- 深拷贝:创建新对象,并递归复制所有嵌套对象
import copy
names = ["Alice", "Bob", "Charlie"]
names_new = names # 不是拷贝 只是创建对同一对象的引用
names_copy = copy.copy(names) # 浅拷贝
names_copy[0] = "Eve" # 只修改副本
print(names) # ['Alice', 'Bob', 'Charlie'] - 原对象不变
print(names_copy) # ['Eve', 'Bob', 'Charlie'] - 浅拷贝创建了新列表,但共享原始元素引用;由于元素是不可变字符串,修改操作实际是创建新对象并更新新列表的引用;原始列表的引用保持不变,因此不受影响
python 内置有哪些数据类型?它们底层分别是什么数据结构?
- List 列表:可变、有序、可迭代、动态指针数组。
- Tuple 元组:不可变、有序、可迭代、定长指针数组。
- Dict 字典:可变、有序、可迭代、哈希表(开放寻址法)。
- Set 集合:可变、无序、可迭代、哈希表(仅键)。
List 拓展有哪些方法有什么区别?
- append:不改变地址,在列表末尾添加新元素。
- insert:不改变地址,在列表的特定位置添加元素。
- extend:不改变地址,通过添加新列表来扩展列表。
- +:创建新地址,将列表的元素连接起来并返回一个新的列表。
Dict 的底层使用什么实现的,查找的时间复杂度是多少?为什么?
dict 的底层是 hashmap 实现的, 查找的时间复杂度为O(1),
双向字典了解嘛,通过 value 找到 key?
Bi-Dictionary 库可以做到
https://mp.weixin.qq.com/s/VOcnZnJ2PWO_smxkK3h7rw
Python 已经有 list 结构为什么还要有 tuple?
- 更省内存。Tuple 在内存和处理速度上都优于 List
- 可哈希。因此 Tuple 可以内嵌在 Dict 里面
- 线程安全。因为 Tuple是只读的, 这就使得它天生能避免读写冲突和写写冲突,在多线程时候可以大胆放心的使用, python底层中也用了很多tuple.
python 是如何管理内存的?
所有的 Python 对象和数据结构都位于一个私有堆中。私用堆的分配由 Python 内存管理器负责。
Python 还内置了一个的垃圾收集器,可以回收未使用的内存并释放内存,使其可用于 headspace。
python 的垃圾回收机制是怎样的?
Python采用的是引用计数机制为主,标记-清除和分代收集两种机制为辅的策略
- 引用计数
当一个对象有新的引用时,对象的引用计数+1;当一个对象的引用被销毁时,对象的引用计数-1。 - 分代回收
将对象按存活时间分为3代(0代最新,2代最老);循环引用导致引用计数不能清零会造成内存泄漏;函数的参数适用了可变变量listdict而默认不是这种可变变量。 - 标记-清除
哪些操作会导致Python内存溢出,怎么处理?
- 所用到C语言开发的底层模块中出现了内存泄漏;
- 代码中用到了全局的list, dict或者其他容器,不停的往这些容器中插入对象,而忘记了在使用完之后进行删除回收
- 代码中存在死循环或循环产生过多重复的对象实体
- 代码中有“引用循环”, 并且被引用的对象定义了
__del__方法, 就会发生内存泄漏;
如何避免循环引用?
如果循环引用中,两个对象都定义了 __del__ 方法,gc模块不会销毁这两个不可达对象,因为gc模块不知道应该先调用哪个对象的 __del__ 方法
例如,两个对象a和b,如果先销毁a,则在销毁b时,会调用b的 __del__ 方法,该方法中很可能使用了a,这时会造成异常,
所以为了安全起见,gc模块会把对象放到 gc.garbage 中,并把它们称为 uncollectable。很明显,这种情况会造成内存泄漏,
要解决的话,只能显式调用其中某个对象的 __del__ 方法来打破僵局。
Python 异步的场景有哪些
- 不涉及共享资源,获对共享资源只读,即非互斥操作
- 没有时序上的严格关系
- 不需要原子操作,或可以通过其他方式控制原子性
- 常用于IO操作等耗时操作,因为比较影响客户体验和使用性能
- 不影响主线程逻辑
解释一下 GIL 锁
强制同一时刻只有一个线程能执行 Python 代码。一个核只能在同一时间运行一个线程。对于io密集型任务,python的多线程起到作用,但对于cpu密集型任务,python的多线程几乎占不到任何优势,还有可能因为争夺资源而变慢
什么是io密集型?什么是cpu密集型?
- IO密集型: 系统运行,大部分的状况是CPU在等 I/O(硬盘 /内存)的读/写(网络请求,读写)
- CPU密集型: 大部分时间用来做计算,逻辑判断等CPU动作的程序称之CPU密集型(数学计算)
解释一下进程、线程、协程
当我们要完成的任务有耗时任务,属于IO密集型任务时,我们使用协程来执行任务会节省很多的资源。
- 进程:一个运行的程序(代码)就是一个进程,没有运行的代码叫程序。各个进程有自己的内存空间、数据栈等。安全性高,但创建和切换开销最大。
- 线程:cpu调度执行的最小单位,不能独立存在,依赖进程存在,一个进程至少有一个线程,叫主线程,而多个线程共享内存(数据共享,共享全局变量),从而极大地提高了程序的运行效率。但受Python的GIL锁限制,多线程无法并行执行CPU任务。
- 协程:是一种用户态的轻量级线程,协程的调度完全由用户控制。协程拥有自己的寄存器上下文和栈。 协程调度时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操中栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快,切换成本极低,可同时处理上万个任务。想要使用协程,那么我们的任务必须有等待。
假设你开了一家快递站:
进程 = 开分店(完全独立,但成本高)
线程 = 雇多个打包员(共享仓库,但受办公室空间限制)
协程 = 一个打包员同时处理多订单(手上打包A→电话联系B→写快递单C)
协程是用户态还是内核态?
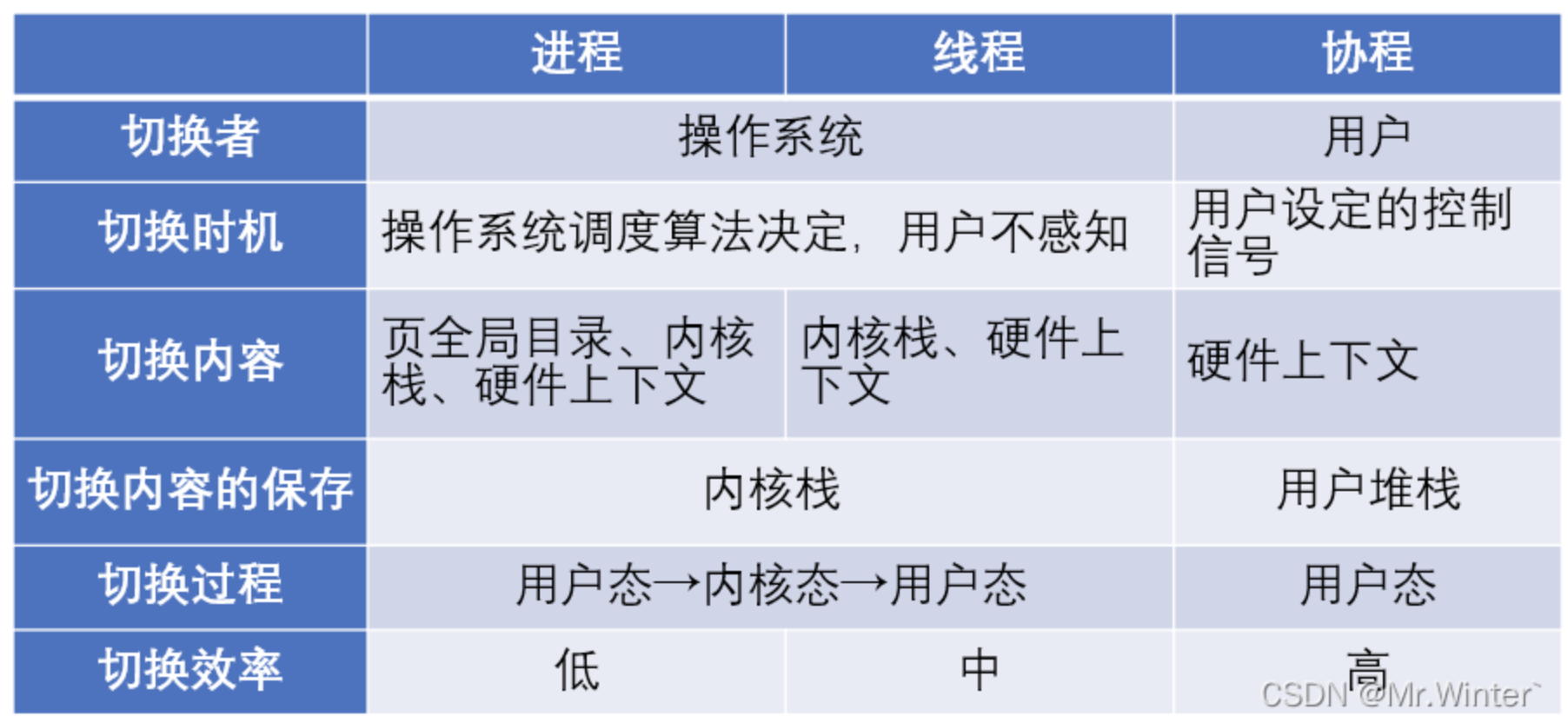 协程就是一种用户态内的上下文切换技术,协程是一种用户态的轻量级线程。
协程就是一种用户态内的上下文切换技术,协程是一种用户态的轻量级线程。
线程是并发还是并行,进程是并发还是并行?
线程是并发,进程是并行; 进程之间互相独立,是系统分配资源的最小单位,同一个进程中的所有线程共享资源。
如何实现并行(parallel)和并发(concurrency)?
实现并行的库有: multiprocessing
实现并发的库有: threading
程序需要执行较多的读写、请求和回复任务的需要大量的IO操作,IO密集型操作使用并发更好。
CPU运算量大的程序,使用并行会更好
python 怎么实现多线程?
python使用threading实现多线程,使用gevent + asyncio实现协程。在Python的进程里只有一个GIL。一个线程需要执行任务,必须获取GIL。
- 好处:直接杜绝了多个线程访问内存空间的安全问题。
- 坏处:Python的多线程不是真正多线程,不能充分利用多核CPU的资源。
为什么携程比进程效率更高?
资源占用极低
- 线程:每个线程需分配 MB 级内存(默认 8MB)和内核资源
- 协程:每个协程只需 KB 级内存(通常 2-10KB),可轻松创建数万个
- 示例:一台普通服务器可运行 10 万协程 vs 最多 2000 线程
切换成本相差千倍
- 线程切换:需通过操作系统内核(用户态→内核态→用户态),耗时 1-10μs
- 协程切换:完全在用户空间由程序控制(无内核参与),耗时仅 0.1-0.3μs
- 协程切换速度是线程的 10-100 倍
无锁编程优势
- 协程在单线程内运行,无需处理多线程的锁竞争(GIL、互斥锁等)
- 避免锁导致的死锁/性能抖动问题
精准控制切换时机
- 协程在 I/O 阻塞时主动让出(yield/await)
- 线程由操作系统强制抢占切换(可能在不合时机切换,导致缓存失效)
假设你要管理 100 项任务:
线程方案 = 雇 100 个员工(线程)
→ 员工越多:
管理成本飙升(调度会议、协调冲突)
办公室空间不足(内存耗尽)
员工频繁换岗消耗时间(切换慢)
协程方案 = 训练 1 个超级员工(单线程)
→ 他处理任务时:
遇到等待(如打电话)立刻切到下一任务(主动让出)
所有任务共享同一桌面的文件(无锁共享内存)
零管理开销(无需协调多人)
结果:超级员工用 1 张桌子完成 100 人的工作,且速度更快!
什么是多线程竞争?
线程是非独立的,同一个进程里线程是数据共享的,当各个线程访问数据资源时会出现竞争状态即:数 据几乎同步会被多个线程占用,造成数据混乱,即所谓的线程不安全
解决多线程竞争问题的关键—锁
- 好处: 确保了某段关键代码(共享数据资源)只能由一个线程从头到尾完整地执行能解决多线程资源竞争下的原子操作问题。
- 坏处: 阻止了多线程并发执行,包含锁的某段代码实际上只能以单线程模式执行,效率就大大地下降了
- 致命问题: 死锁
什么是死锁?
若干子线程在系统资源竞争时,都在等待对方对某部分资源解除占用状态,结果是谁也不愿先解锁,互相干等着,程序无法执行下去,这就是死锁。
GIL全局解释器锁的作用: 限制多线程同时执行,保证同一时间只有一个线程执行,所以cython里的多线程其实是伪多线程。
所以python里常常使用协程技术来代替多线程,进程和线程的切换时由系统决定,而协程由我们程序员自己决定,而模块gevent下切换是遇到了耗时操作时才会切换。
三者的关系:进程里有线程,线程里有协程。
Python 的多线程和多进程的应用场景和优缺点?
-
应用场景: 线程是操作系统分配CPU的基本单位,进程是操作系统分配内存的基本单位。
通常我们运行的程序会包含一个或多个进程,而每个进程中又包含一个或多个线程。
多线程的优点在于多个线程可以共享进程的内存空间,所以线程间的通信非常容易实现;但是多线程受制于GIL,并不能利用CPU的多核特性。
使用多进程可以充分利用CPU的多核特性,但是进程间通信相对比较麻烦,需要使用IPC机制(管道、套接字等)。 -
优缺点: 多线程适合那些会花费大量时间在I/O操作上,但没有太多并行计算需求且不需占用太多内存的I/O密集型应用。
多进程适合执行计算密集型任务(如:视频编码解码、数据处理、科学计算等)、可以分解为多个并行子任务并能合并子任务执行结果的任务以及在内存使用方面没有任何限制且不强依赖于I/O操作的任务。
python 的多线程不是真正的多线程,为什么还要用?
只是不适合 CPU 密集型但是 IO 密集型使用多线程有两个好处:CPU并行,IO并行。
Python虽然不能利用多线程实现多核任务,但可以通过多进程实现多核任务。多个Python进程有各自独立的GIL锁,互不影响。
多核多线程比单核多线程更差,原因是单核下的多线程,每次释放GIL,唤醒的那个线程都能获取到GIL锁,所以能够无缝执行,但多核下,CPU0释放GIL后,其他CPU上的线程都会进行竞争,
但GIL可能会马上又被CPU0拿到,导致其他几个CPU上被唤醒后的线程会醒着等待到切换时间后又进入待调度状态,这样会造成线程颠簸(thrashing),导致效率更低
在多线程并发访问一批数据时,如何确保每个数据仅被一个线程处理一次(避免重复访问)?
创建一个已访问数据列表,用于存储已经访问过的数据,并加上互斥锁,在多线程访问数据的时候先查看数据是否在已访问的列表中,若已存在就直接跳过。
如何最大性能执行 python
多进程适合在 CPU 密集操作(cpu操作指令比较多,如位多的的浮点运算)。
多线程适合在 IO 密性型操作(读写数据操作比多的的,比如爬虫)
为什么python代码执行缓慢?
因为它是一种解释型语言。它的代码在运行时进行解释,而不是编译为本地语言。 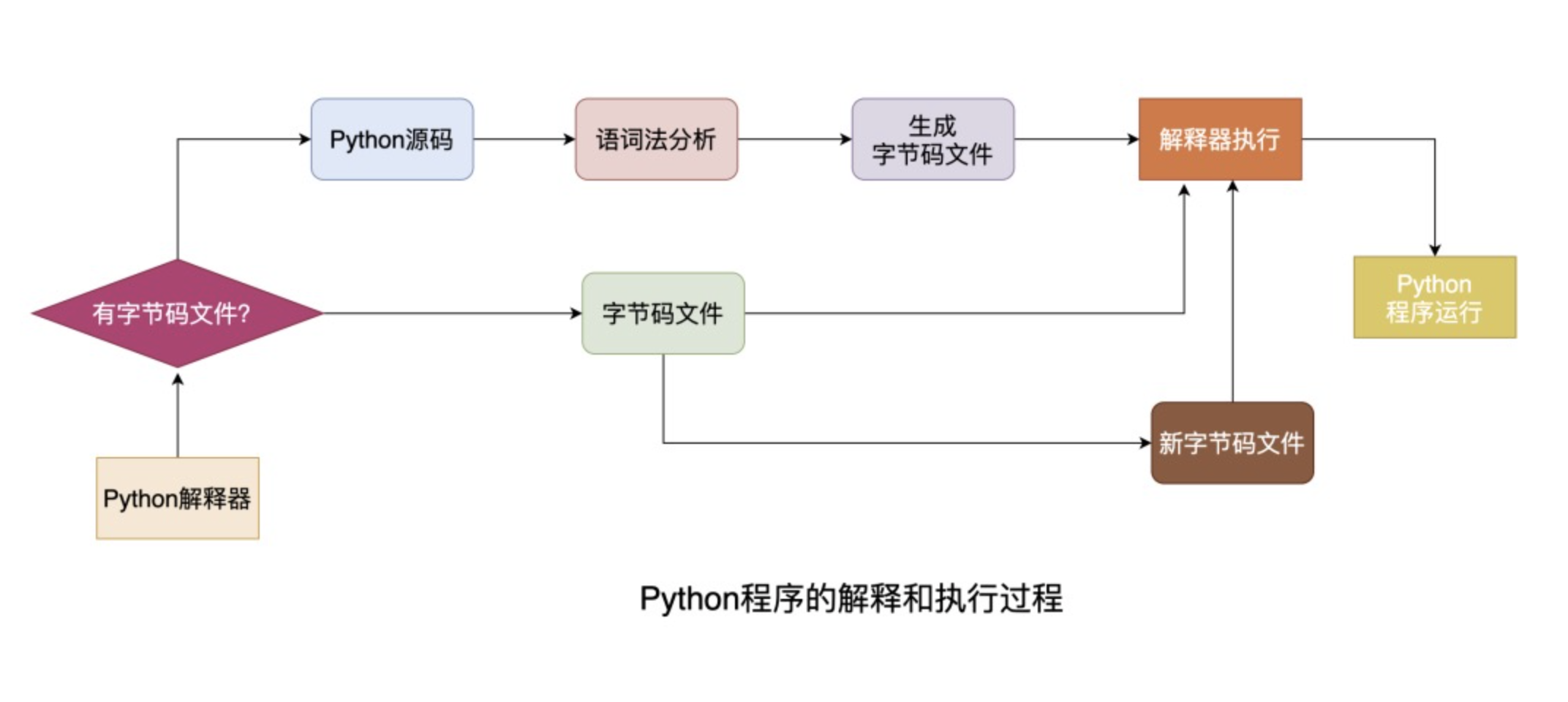
如何提高执行速度?
可以使用CPython、Numba,或者我们也可以对代码进行一些修改。首先看瓶颈在哪里,如果在CPU计算比较重可以用c实现一下;
如果是跟code关系不大主要是网络数据库这一块,就要看sql语法和协程调用有没有充分使用;line_profiler 在code里写上可以帮助分析这一块的性能;
cProfiler 帮助分析整体性能;火焰图
python 的第三方库 Pipe 有用过吗?
https://mp.weixin.qq.com/s/eoctrMLuxPNd8bWJvenM6Q
python 内置的弱引用 weakref 了解吗?
https://mp.weixin.qq.com/s/kS4QEt8rVfuuGx5CX1_Kew
uv 这个包了解吗?
https://xuyuanzhe.github.io/blog/2025/uv/
Python 实现定时任务有哪些方案?
https://mp.weixin.qq.com/s/R711eavHKBbvPlZXtUZ8Dg
time.sleep(0) 这个看似”零休眠”的代码,在实际编程中有什么用途?
time.sleep(0) 本质是 “零延迟的线程/协程调度提示器”,用于优化程序并发行为,避免资源独占,是多线程/异步编程中的重要技巧。
import time
time.sleep(0) # 实际执行过程:
1. 线程进入内核态
2. 触发系统调用:nanosleep(&(struct timespec){0}, NULL)
3. 内核立即将线程放回就绪队列
4. 触发线程调度器重新分配CPU
解释一下 *args **kwargs 是什么?
它们是 Python 中的可变参数和关键字参数的语法糖。
- *args:收集位置参数到元组 (tuple)
- **kwargs:收集关键字参数到字典 (dict)
- 单星*解包序列,双星**解包字典
def demo_args(a, b, *args, **kwargs):
print(f"标准参数: {a}, {b}")
print(f"位置参数 (*args): {args} (类型: {type(args)})")
print(f"关键字参数 (**kwargs): {kwargs} (类型: {type(kwargs)})")
demo_args(1, 2, 3, 4, 5, name="Alice", age=30)
# 输出:
# 标准参数: 1,2
# 位置参数 (*args): (3, 4, 5) (类型: <class 'tuple'>)
# 关键字参数 (**kwargs): {'name': 'Alice', 'age': 30} (类型: <class 'dict'>)
程序设计
你知道的几种设计模式?
- 单例模式:保证一个类仅有一个实例,并提供一个访问他的全局访问点,例如框架中的数据库连接
- 装饰器模式:不修改元类代码和继承的情况下动态扩展类的功能,例如框架中的每个controller文件会提供before和after方法。
- 迭代器模式: 提供一个方法顺序访问一个聚合对象中各个元素。
- 命令模式: 将”请求”封闭成对象, 以便使用不同的请求,队列或者日志来参数化其他对象. 命令模式也支持可撤销的操作.
手写一个单例模式?说说理解
class Singleton(object):
def __new__(cls, *args, **kwargs):
if not hasattr(cls, '_instance'):
orig = super(Singleton, cls)
cls._instance = orig.__new__(cls, *args, **kwargs)
return cls._instance
class MyClass(Singleton):
a = 1
通过单例模式可以保证系统中一个类只有一个实例而且该实例易于外界访问,从而方便对实例个数的控制并节约系统资源。如果希望在系统中某个类的对象只能存在一个,单例模式是最好的解决方案。
Django 和 Tornado 的关系、差别在哪里?
- 并发模型:Django 基于多线程 / 多进程(同步阻塞),处理高并发需依赖 Gunicorn+Nginx 等;Tornado 是单线程异步非阻塞模型,原生支持高并发 IO(如长连接、WebSocket)。
- 功能完备性:Django 是 “全栈框架”,内置 ORM、Admin 后台、表单验证等全套工具,开箱即用;Tornado 更轻量,仅提供核心 Web 组件(路由、模板等),需自行集成其他工具。
- 适用场景:Django 适合快速开发复杂业务系统(如 CMS、电商后台);Tornado 适合高并发场景(如实时通讯、API 服务)。
MVC / MTV;
Model View Controller
Model Template View
中间件是干什么用的?
中间件是系统中连接不同组件、处理通用性功能的中间层,核心作用是解耦和复用以及处理共性问题(日志、鉴权、缓存)和适配异构系统。
CSRF是什么,django是如何避免的;XSS呢?
- CSRF(跨站请求伪造):诱导用户在已登录网站执行非本意操作
- Django 通过 CsrfViewMiddleware 中间件,强制验证表单或请求头中的 CSRF 令牌防御。
- XSS(跨站脚本攻击):注入恶意脚本窃取信息。
-
Django 模板默认自动转义变量(如 < 转成 <),需主动输出 HTML 时用 safe 标记(谨慎),并过滤用户输入危险内容。
-
如果你来设计login,简单的说一下思路?
前端:
- 展示账号输入框(账号、密码)+ 提交按钮
- 输入验证(非空、格式校验)
- 防重复提交(按钮置灰)
后端:
- 接收账号密码,验证合法性(查数据库)
- 验证通过:生成 session_id(或 JWT 令牌),返回给客户端(存 cookie 或 localStorage)
- 验证失败:返回错误信息(不暴露具体原因)
- 安全措施:密码加盐哈希存储、防暴力破解(限流 / 验证码)、CSRF 防护
状态维持:
- 客户端后续请求携带凭证(session_id/JWT)
- 服务器验证凭证有效性,确认用户身份
session和cookie的联系与区别;session为什么说是安全的?
联系:
- 都用于保持用户状态(如登录状态),session 通常依赖 cookie 传递 session_id(标识用户)。
区别:
- 存储位置:cookie 存在客户端(浏览器),session 存在服务器;
- 安全性:cookie 易被篡改 / 窃取,session 数据在服务器更安全;
- 容量:cookie 大小受限(约 4KB),session 容量更大。
session 为何更安全
- 核心数据(如用户信息)存储在服务器,客户端仅存 session_id(随机字符串),攻击者无法直接获取敏感数据;
- session_id 可设置过期时间,且服务器可主动销毁无效 session,降低被盗用风险;
- 相比 cookie,session 不易被客户端篡改(数据在服务器端验证)。
能不能说几种token过期后的续期方案?
- 粗暴续期。token过期后通过期了跳登录页让用户手动的续期,这是一个很不友好的一个续期方案,因为不管是你跳登录页,还是弹出来一个登录窗口,虽然在功能的实现上比较简单,但是大大的牺牲了用户的体验,所以一般不推荐使用这种方案。
- 前端重新请求刷新token。前端发现token到了过期时间,此时前端在发一个刷新的token的请求,服务端重新生成一个新的token并将这个新的token响应给前端,前端拿到新的token后再把原先的请求重新发送到服务端。这种实现方案是通过前端的实现token的用户无感续期。
- 但是这种方案会带来一个比较棘手的问题,那就是用户一直不用登录了,因为不管这个用户多久没有登录,只要发现token过期了,前端请求刷新token后获取到新的token,那么用户就可以再次请求服务器获取到数据,这种实现方案在产品设计上是不符合要求的。
- 服务端刷新token。服务端生成token的时候会设置一个过期时间(如设置成了3小时有效),每当用户登录成功后,用户每次发送请求服务端都刷新一个新token给客户端,那新的token又是3小时过期,此时只要用户3小时内请求了系统,那token的有效期就会一直自动的续期。
- 此方案也存在一定的缺陷,因为用户每次请求都刷新token的话,压力就会给到服务器,特别是在高并发的情况下,这种方式是不可取的。
- redis记录token过期时间。服务端颁发给客户端的token现在不设置过期时间了,换句话说就是生成token的时候不再有过期时间的概念,我们将过期时间使用redis来记录,此时如果用户请求过来之后,在redis里面给这个token去自动完成续期操作。
- 这种方案也存在一个弊端,原先我们前后端分离后,服务端颁发的这个token是让客户端去验证身份,也就是验证身份的工作交给客户端处理,但是现在这种方案又需要服务端在redis中维护用户身份,违背了设计的初衷。
- 双token机制。当用户在登录成功之后,服务端生成并返回两个token给客户端,其中token1是用户执行业务请求访问服务器的时候使用,假设设置过期时间为24小时;token2是用于给的token1和token2续期的时候使用。
- 当token1过期之后开始启用token2,客户端携带token2请求服务器刷新token,服务器针对token2有如下的执行逻辑:
- 如果服务端验证token2没有过期,那认定用户还是活跃用户。此时服务端正常的生成并返回两个新的token(token1和token2,并且设置对应的过期时间),此时用户还可以请求服务器执行业务逻辑。
- 如果token2刷新的时候,服务端发现token2也过期了。 这个时候,我们就需要强制要求用户重新的登录系统,服务器再颁发两个新的token给客户端。
- 当token1过期之后开始启用token2,客户端携带token2请求服务器刷新token,服务器针对token2有如下的执行逻辑:
什么是WSGI,uwsgi,uWSGI?
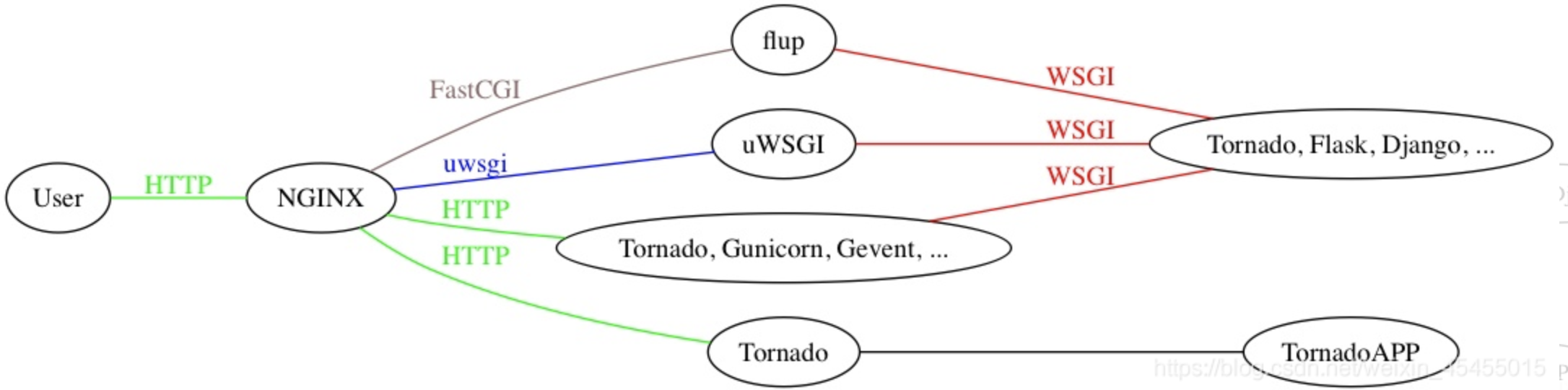
- WSGI: web服务器网关接口,是一套协议。用于接收用户请求并将请求进行初次封装,然后将请求交给web框架。实现wsgi协议的模块:wsgiref,本质上就是编写一socket服务端,用于接收用户请求(django)
- uwsgi: 与WSGI一样是一种通信协议,它是uWSGI服务器的独占协议,用于定义传输信息的类型。
- uWSGI: 是一个web服务器,实现了WSGI的协议,uWSGI协议,http协议
为什么有了uWSGI为什么还需要nginx?
因为nginx具备优秀的静态内容处理能力,然后将动态内容转发给uWSGI服务器,这样可以达到很好的客户端响应。
介绍下你知道的负载均衡相关的算法?
- 轮询 将所有请求,依次分发到每台服务器上,适合服务器硬件相同的场景。
优点:服务器请求数目相同;
缺点:服务器压力不一样,不适合服务器配置不同的情况; - 随机 请求随机分配到各台服务器上。
优点:使用简单;
缺点:不适合机器配置不同的场景 - 最少链接 将请求分配到连接数最少的服务器上(目前处理请求最少的服务器)。
优点:根据服务器当前的请求处理情况,动态分配;
缺点:算法实现相对复杂,需要监控服务器请求连接数; - Hash(源地址散列) 根据IP地址进行Hash计算,得到IP地址。
优点:将来自同一IP地址的请求,同一会话期内,转发到相同的服务器;实现会话粘滞。
缺点:目标服务器宕机后,会话会丢失; - 加权 在轮询,随机,最少链接,Hash等算法的基础上,通过加权的方式,进行负载服务器分配。
优点:根据权重,调节转发服务器的请求数目;
缺点:使用相对复杂;
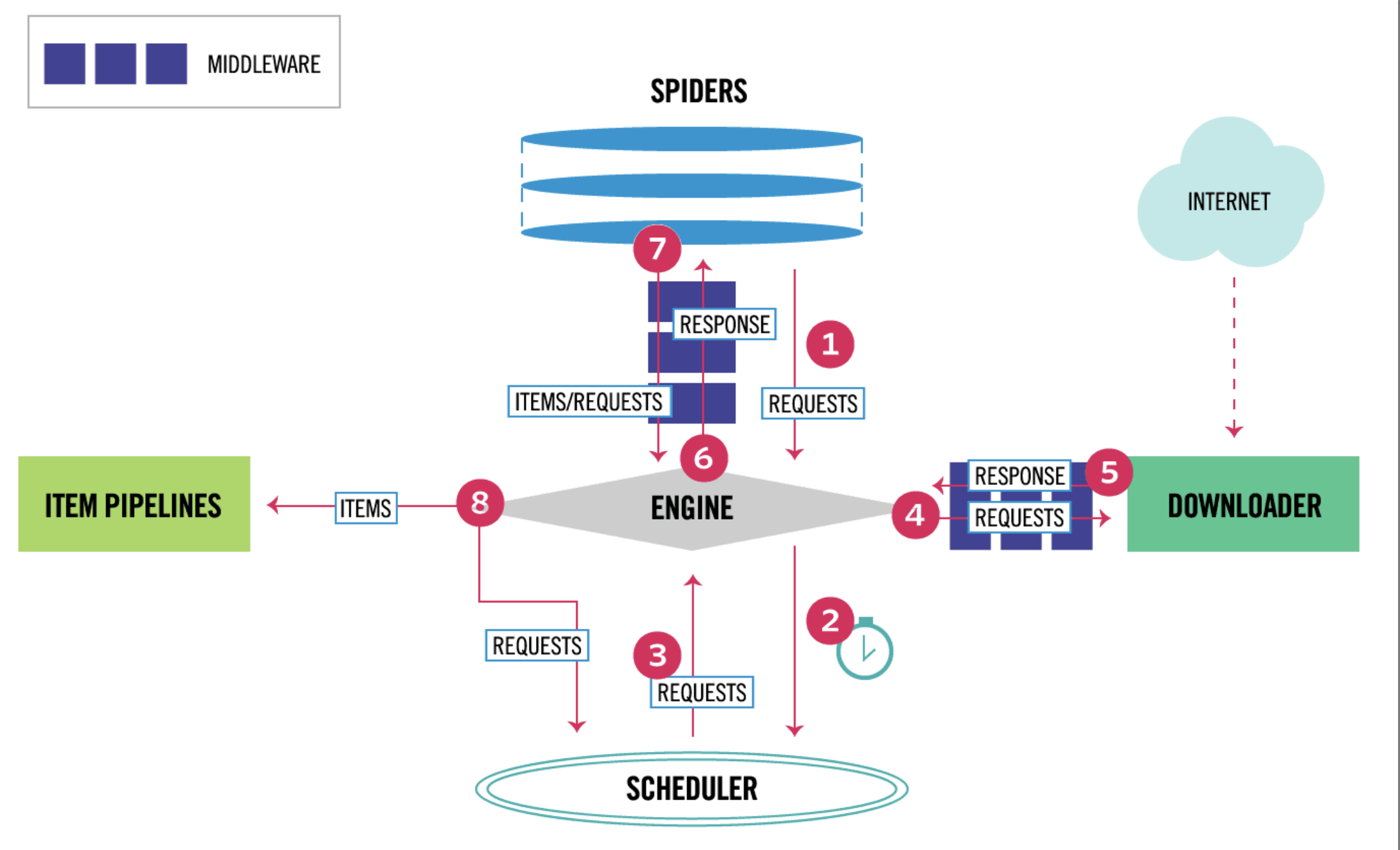
画出 scrapy 框架工作流程
网安
解释 PoC & EXP 分别是什么?
POC是⽤来证明漏洞存在的,EXP是⽤来利⽤漏洞的,两者通常不是⼀类,或者说,PoC通常是⽆害的,Exp通常是有害的,有 了POC,才有EXP。
想象⾃⼰是⼀个特⼯,你的⽬标是监控⼀个重要的⼈,有⼀天你怀疑⽬标家⾥的窗⼦可能没有关,于是你上前推了推,结果推开 了,这是⼀个PoC。之后你回去了,开始准备第⼆天的渗透计划,第⼆天你通过同样的漏洞渗透进了它家,仔细查看了所有的重 要⽂件,离开时还安装了⼀个隐蔽的窃听器,这⼀天你所做的就是⼀个EXP,你在他家所做的就是不同的Payload,就把窃听器当作Shellcode吧!
https://mp.weixin.qq.com/s/p7aOrpvustNYslCYGz5_iw https://mp.weixin.qq.com/s/c11Z612tZHzpeFfvO5NmpA https://mp.weixin.qq.com/s/0rATDy-rjL9SVR3doR7MMg