有关于人工智能
自动化 L1 - L5 是如何划分?
- L1: 辅助自动化,AI 简化流程,提供工具支持。
- L2 - L3: 部分自动化,能独立生成内容但需人类设定条件。
- L4: 高级自动化,AI 独立创作,有一定创新能力。
- L5: 无安全自动化,AI 超越人类水平具备自我反思与创新能力
什么是大语言模型 LLM ?
语言模型简单说来,就是对人类的语言建立数学模型,语言模型是一个由数学公式构建的模型,并不是什么逻辑框架。
让计算机理解人类的语言,不是像教人那样教它语法,而是最好能够让计算机计算出哪一种可能的语句概率最大。 这种计算自然语言每个句子的概率的数学模型,就是语言模型。
数学模型如何计算概率?
- 阶段一:统计语言模型(Statistical Language Model,SLM)
- 阶段二:神经网络语言模型(Neural Language Model,NLM)
- 阶段三:预训练语言模型(Pre-trained Language Model,PLM)
- 阶段四:大语言模型(Large Language Model)
语言模型本质上都是在计算自然语言每个句子的概率的数学模型。当你输入一个问题给 AI 时,AI 就是用概率算出它的回答。
当今的语言模型,并不是一个问题对一个答案,实际上是一个问题,多个答案,然后根据答案的概率进行排序,最后返回一个最可能的答案。
开发大语言模型需要什么?
- 关键一:数据
- 关键二:算法(Transformers、DeepSpeed、Megatron-LM、JAX…)
- 关键三:算力
大语言模型有什么缺点?
- 缺点一:结果高度依赖训练语料
- 缺点二:Hallucinations(幻觉)胡说八道…
- 缺点三:暂时只能解决数学问题 出现无法预测的问题无法处理
什么是智能体 Agent?
智能体 = 自治实体(感知→决策→执行) + 目标导向 + 环境交互
一个能独立完成任务的“AI员工”。 能够感知环境、推理规划任务、调用工具(MCP Server & Function Call)、从过往经历汲取经验并完成目标。
什么是函数调用 function calling?
一种机制,允许大语言模型 LLM 直接调用预定义函数的能力,允许模型生成参数并整合结果。
什么是模型上下文协议 MCP ?
MCP,全称为 Model Context Protocol,是一个开源的协议标准。
什么是 A2A?
A2A(Agent-to-Agent)是指智能体之间的直接交互和协作。它允许不同的智能体在没有人类干预的情况下相互通信、共享信息和执行任务。A2A 的核心在于智能体能够理解彼此的意图和能力,从而实现高效的协同工作。
架构如下: 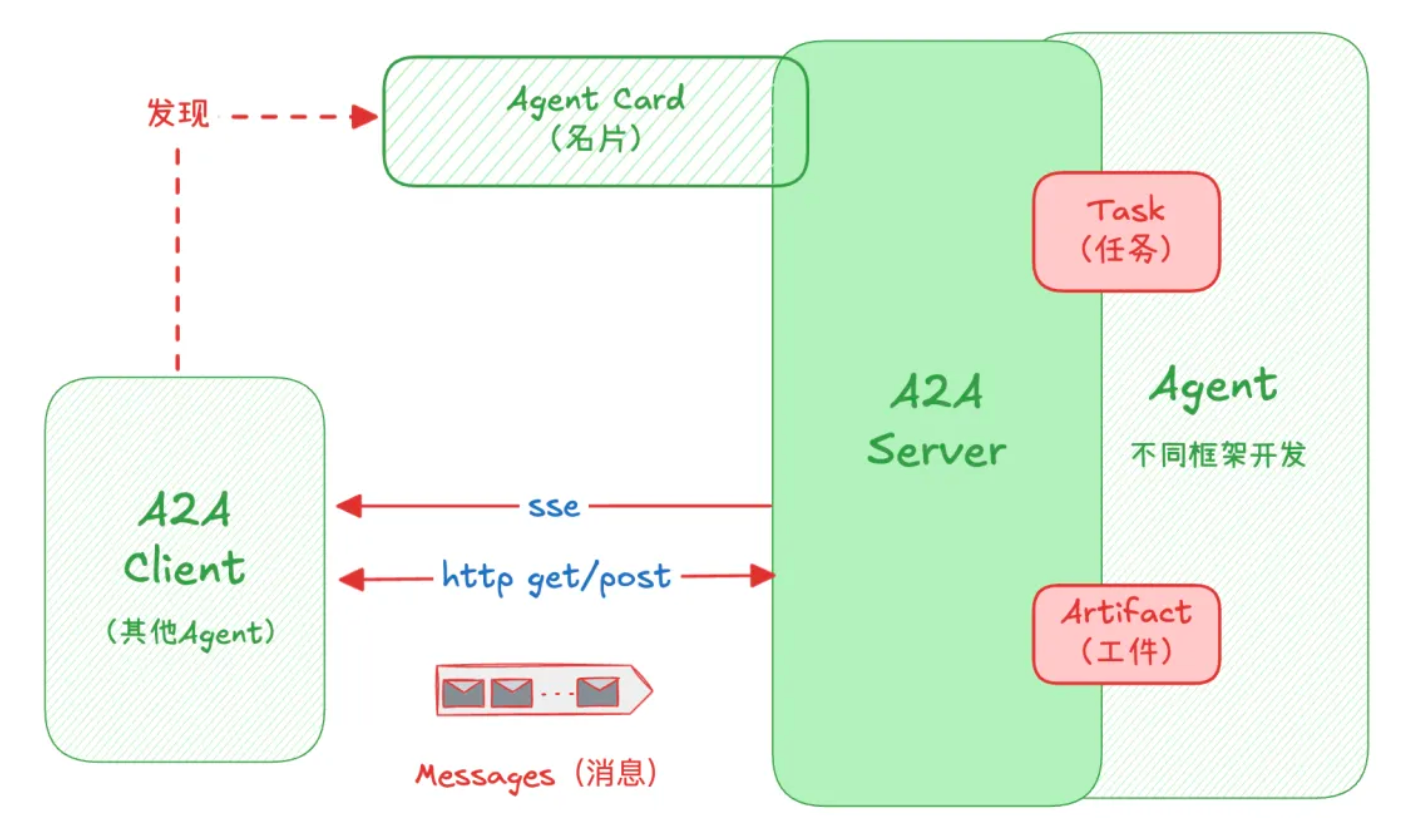
- Agent Card(智能体卡片):相当于每个智能体对外公布的“服务说明书”和“名片”。描述智能体的名称、版本、调用端点、具备的技能、所需的认证方式等。
- A2A Server:用来将一个Agent通过A2A协议对外开放的Server。接受任务请求并给予响应或通知;相对于MCP Server开放工具,A2A Server则开放出Agent。
- A2A Client:访问A2A Server的其他Agent。可见Client与Server是相对的,一个客户端Agent同时也可以通过A2A Server开放给其他应用。
- 任务模型:服务端 Agent 实现标准的任务接口,负责接收并处理任务请求,管理任务状态并推送结果;客户端 Agent 则通过HTTP调用服务端 Agent的这些接口。
- 任务流程:任务通常按以下状态流转:已提交 (submitted) → 处理中 (working) → (可能需要额外输入 input-required)→ 完成 (completed) 或失败 (failed) 。A2A支持异步任务协作:有完善的通知和回调机制。
- 交换内容:交互过程中双方可以交换消息和工件两类内容:消息可以包含文本、文件、结构化数据等多种形式内容;而工件则代表任务产出的最终结构化结果。
什么是思维链 Chain-of-Thought ?
思维链是一种引导大模型进行逐步推理的提示工程技术,通过要求模型展示从问题到答案的完整思考过程,来提高复杂问题的解决能力。 这种方法特别适用于需要多步逻辑推理的任务,如数学问题求解、逻辑分析和复杂决策。思维链技术显著提升了模型在需要深度思考的任务上的准确性和可解释性。 模拟了人类解决问题的方法步骤,通过思考过程和任务分解等方法来解决复杂任务。
什么是检索增强生成 RAG?
Retrieval-Augmented Generation 是一种将信息检索与文本生成结合的技术框架。其工作流程分为三步:
- 检索(Retrieval):将用户查询转化为向量,从外部知识库中匹配相关文档片段;
- 增强(Augmentation):将检索结果与原始查询组合成新提示(Prompt);
- 生成(Generation):语言模型基于增强后的提示生成答案。
它为解决传统大语言模型(LLM)的三大缺陷:
- 知识时效性差:训练数据截止后新信息无法回答(如2023年训练的模型不知2025年政策);
- 幻觉(Hallucination):模型编造看似合理实则错误的事实(如虚构法律案例);
- 无法访问私有数据:企业内部的专有知识(如产品手册、客户数据)无法被通用模型调用。
RAG 解决 “AI知道什么”(知识来源问题)
什么是序列认知类型理论 RFC?
Sequence CognitiveType Theory 提出一个新的认知理论:思维模式本质上是认知类型的编舞。每种思维模式都是 ATOMIC、LINK、PATTERN 三种认知类型的特定序列组合。
RFC 解决 “AI如何思考”(认知路径问题)
老虎机 vs Vibe Coding 怎么更合理使用 AI 工具?
合理运用 AI 辅助的关键是在每个环节都保持技术判断力,而不是把决策权交给AI。
| 老虎机 | Vibe Coding | 抓娃娃 | AI辅助编程 |
|---|---|---|---|
| 买代币(Tokens) | 买 Tokens | 买游戏币 | 买 Tokens + 技术积累 |
| 拉动拉杆 | 写一段模糊的提示词,然后点击”生成” | 仔细观察娃娃位置,精准操作摇杆 | 明确需求描述,让AI生成代码,然后review和优化 |
| 可能中大奖,也可能一无所获 | 可能得到完美应用,也可能是混乱代码 | 可能抓到心爱的娃娃,也可能抓了个寂寞 | 得到高质量、可维护的代码解决方案 |
| 没有测试,全凭开奖结果 | “能跑就行”,出问题再说 | 当场就能看出抓没抓到 | 完整的测试流程,问题提前发现 |
| 闪烁的灯光!”大奖!”铃声! | “绝妙的主意!”“完美解决方案!” | 成功的”咔嚓”声和娃娃掉落的满足感 | “测试通过,代码质量良好,可以部署了” |
| “我有一套自己的赢钱系统” | “我是一个提示词工程师” | “我研究过爪子的抓力和娃娃的重心” | “我懂业务逻辑,AI帮我提高开发效率” |
| “再玩一次,我一定能赢回来” | “再试一次提示词,这次肯定能修复这个Bug” | “这个角度不对,让我调整一下策略” | “让我分析问题根因,然后优化代码逻辑” |
| 庄家总是赢家 | 模型厂商总是赢家 | 游戏厅老板总是赢家,但技术好的确实能多抓几个 | 程序员和用户都受益,技术能力持续提升 |
| 轻松赚钱:”我赢了100万美元大奖!” | 轻松编程:”我一个周末搭建了完整的SaaS!” | 技术展示:”看我这套连抓技巧,成功率30%!” | 效率提升:”这个功能用AI辅助,2小时完成了以前2天的工作” |
| “过去4小时去哪儿了?” | “我花3小时生成一个20分钟就能写的函数?” | “虽然花了1小时,但我真的抓到了限量版!” | “包括需求分析、编码、测试,总共用了半天时间” |
| 技术能力占比:0% | 技术能力占比:10% | 技术能力占比:40% | 技术能力占比:80% |
| 运气依赖:100% | 运气依赖:90% | 运气依赖:60% | 运气依赖:20% |
TIP
进阶之路在于转变
-
心态转变:从”AI帮我写代码”到”我用AI优化编程”
- 以前的想法:让AI帮我写代码,我负责调用
- 现在的想法:我主导整个开发过程,AI提高我的效率
- 技能转变:从”提示词工程师”到”AI时代的程序员”
- 需求分析能力:把业务需求转化为清晰的技术需求
- 代码review能力:能快速判断AI生成代码的质量
- 系统设计能力:知道如何拆解复杂问题
- 测试思维:每个功能都要考虑测试用例
- 工作流程的改变
- 传统开发:需求分析 → 设计 → 编码 → 测试 → 部署
- AI辅助开发:需求分析 → 任务拆解 → AI辅助编码 → 实时review → 测试验证 → 部署